Problem 3. (30 pts)¶
Task 1 (10 pts)¶
For FCNN (Fully connected Neural Networks) \begin{equation} f(x)=f_k\left(f_{k-1}\left(\ldots\left(f_0(x)\right)\right),\right. \end{equation} assume the nonlinearity function $\sigma$ is ReLU and loss function $L$ is squared error loss function. Prove that the deep learning model is not unique for any datasets, i.e. the optimization problem \begin{equation} \min_\theta \ g(\theta)=\frac{1}{N} \sum_{i=1}^N L\left(y_i, \hat{y}_i\right), \text{where} \ \ \hat{y}_i=f\left(x_i, \theta\right), \end{equation} dose not have an unique global minimizer $\theta$.
Task 2 (5 pts)¶
The softmax activation function is \begin{equation} \mathrm{Softmax}(\mathbf{z})_i=\frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} \ \text { for } \ i=1, \ldots, K \text { and } \mathbf{z}=\left(z_1, \ldots, z_K\right) \in \mathbb{R}^K. \end{equation} Suppose $\mathbf{z} \in \mathbb{R}^K$, and $\mathbf{a} \in \mathbb{R}^K$, Prove that for the optimization problem \begin{equation} \begin{aligned} & \min_{\mathbf{a}} \ -\langle\mathbf{a}, \mathbf{z}\rangle+\langle\mathbf{a}, \log \mathbf{a}\rangle \\ & \text { s.t. } \sum_k^K \mathbf{a}_{k}=1, \end{aligned} \end{equation} the minimizer is \begin{equation} \mathbf{a}^*=\mathrm{Softmax}(\mathbf{z}). \end{equation}
Hint: KKT optimality conditions and convexiy of the problem can help you to show the required equality
Task 3 (15 pts)¶
For function $f(x)=x^2, x \in \left[0, 1\right]$,
- prove that the neural network $\hat f(x)$ based on the following structure has the approximation error
where $n$ is the number of layers in the neural network.
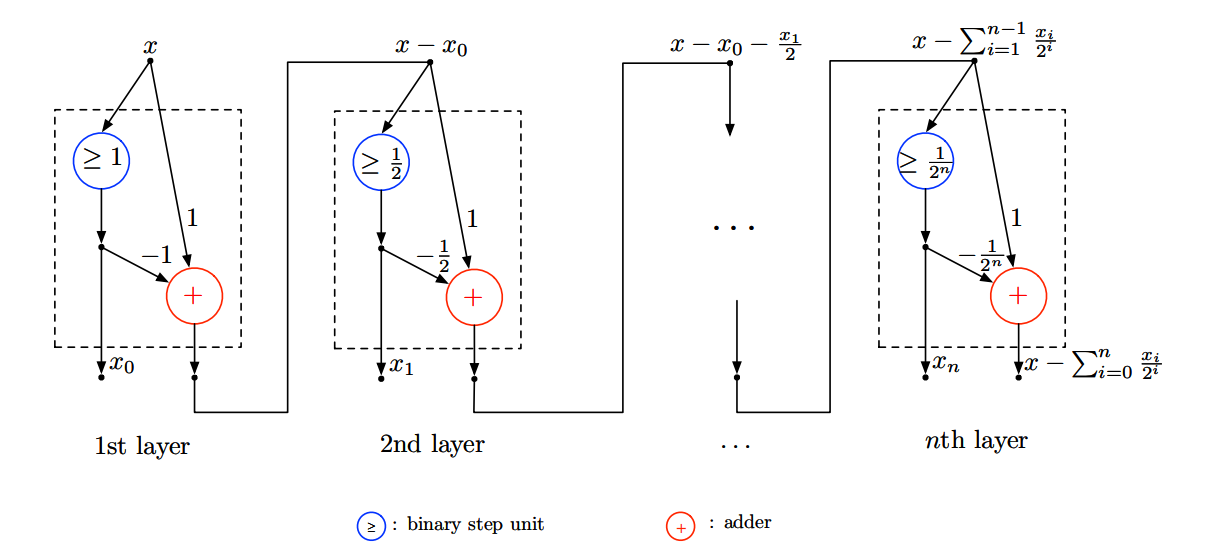
Hint: For each $ x \in \left[0, 1\right]$, $x$ can be denoted by its binary expansion $x=\sum_{i=0}^{∞} x_i/2^i$, where $x_i \in \{ 0, 1\}$. The above structure can be used to find $x_0,\dots, x_n$. Then we can write $\hat f(x)=f\left(\sum_{i=0}^{∞} x_i/2^i\right).$
After the proof, if we want to achieve $\epsilon$ appoximation error based on the above neural network, the number of layers $n$ has to satisfy the condition $\frac{1}{2^{n-1}}\leq \epsilon$, i.e. $n\geq \log_2 \frac{1}{\epsilon}$.
- Implement this neural network in any framework you like with different $n$ (for example $n = 3, 5, 10, 15$), and then plot the curve for absolute errors for different $n$. Compare the obtained plots with theoretical bound.