Deep learning architectures¶
The parametrization of the model $f(x, \theta)$ is the key ingredient.
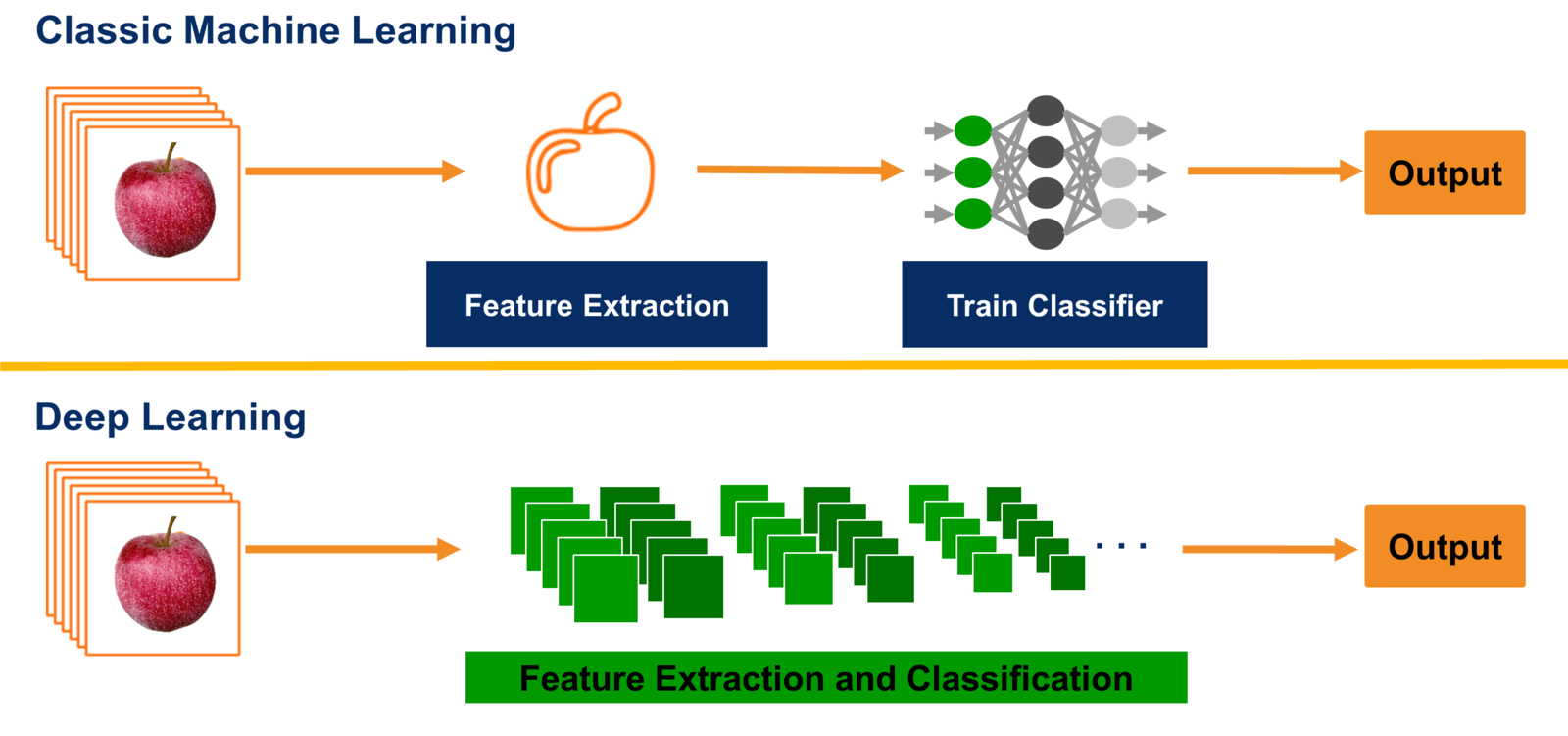
The standard approach of 'classical' machine learning is to design a certain map $E(x)$ with comes from the expert knowledge.
Then, learn a simple (i.e., linear) model
$$y = f(E(x), \theta)$$.
The concept of end-to-end learning is to avoid predesigned feature engineering, rather than consider parametric building blocks, and learn them simultaneously.
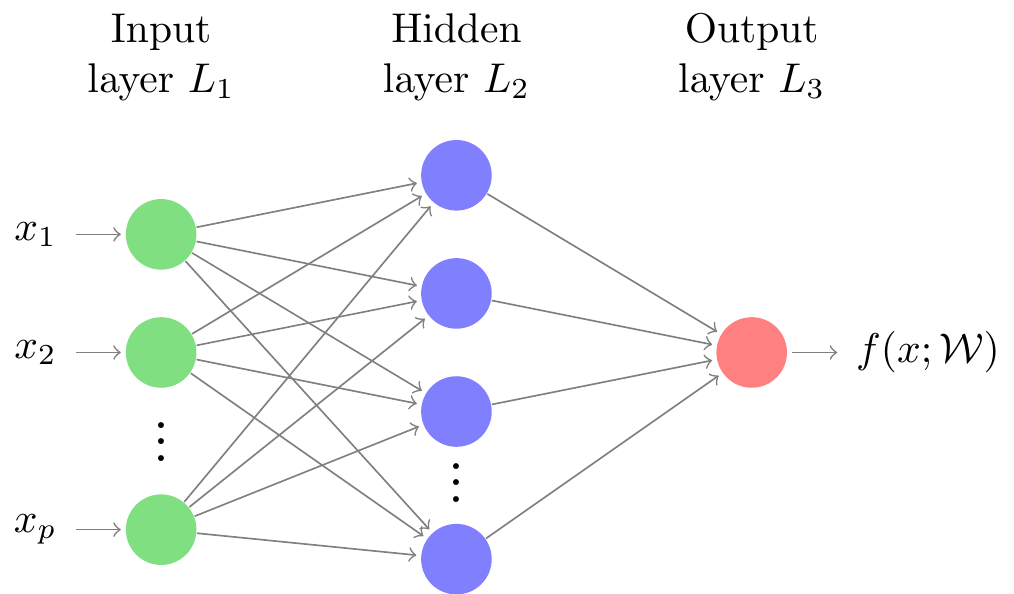
The simplest representation of this form is feedforward neural networks.