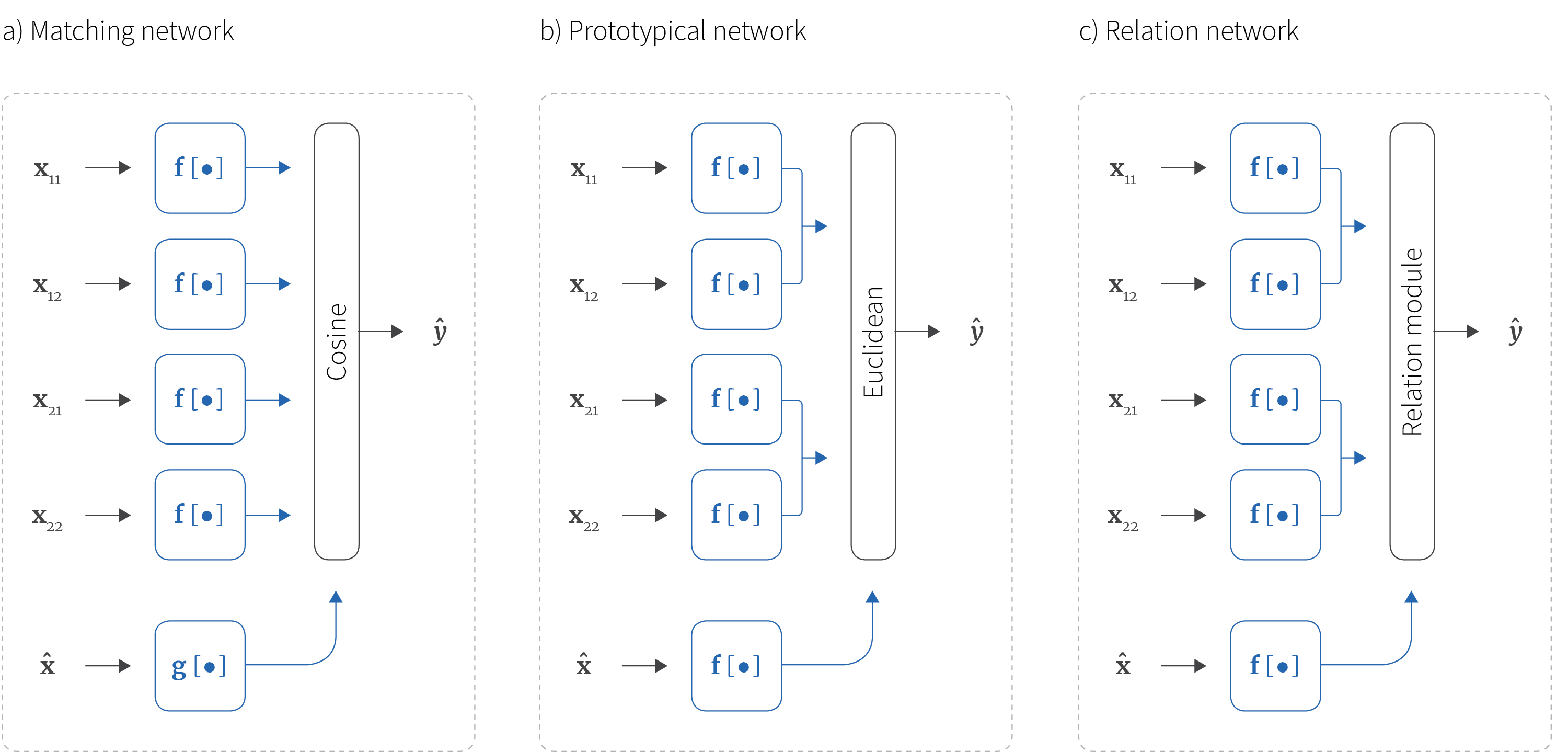
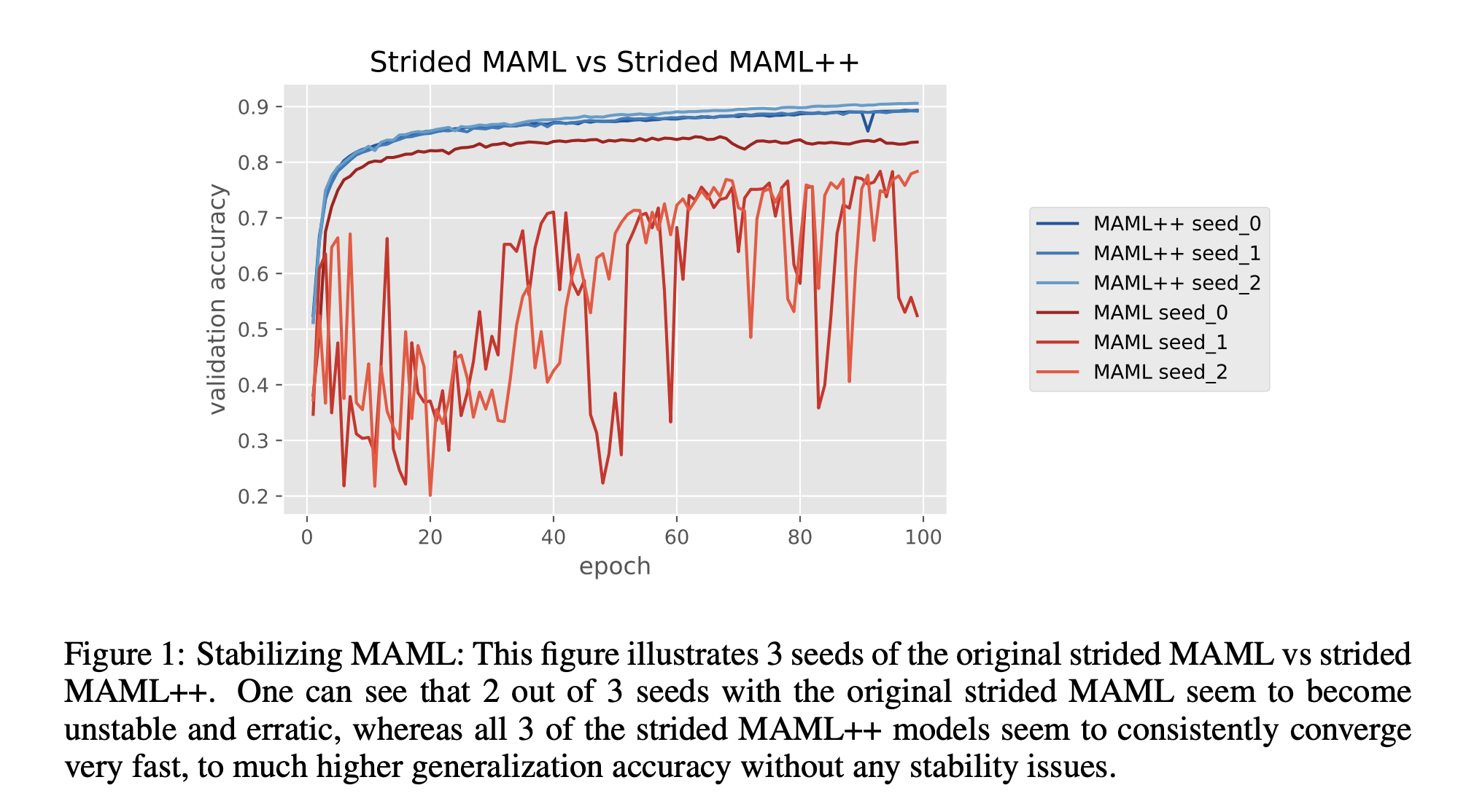
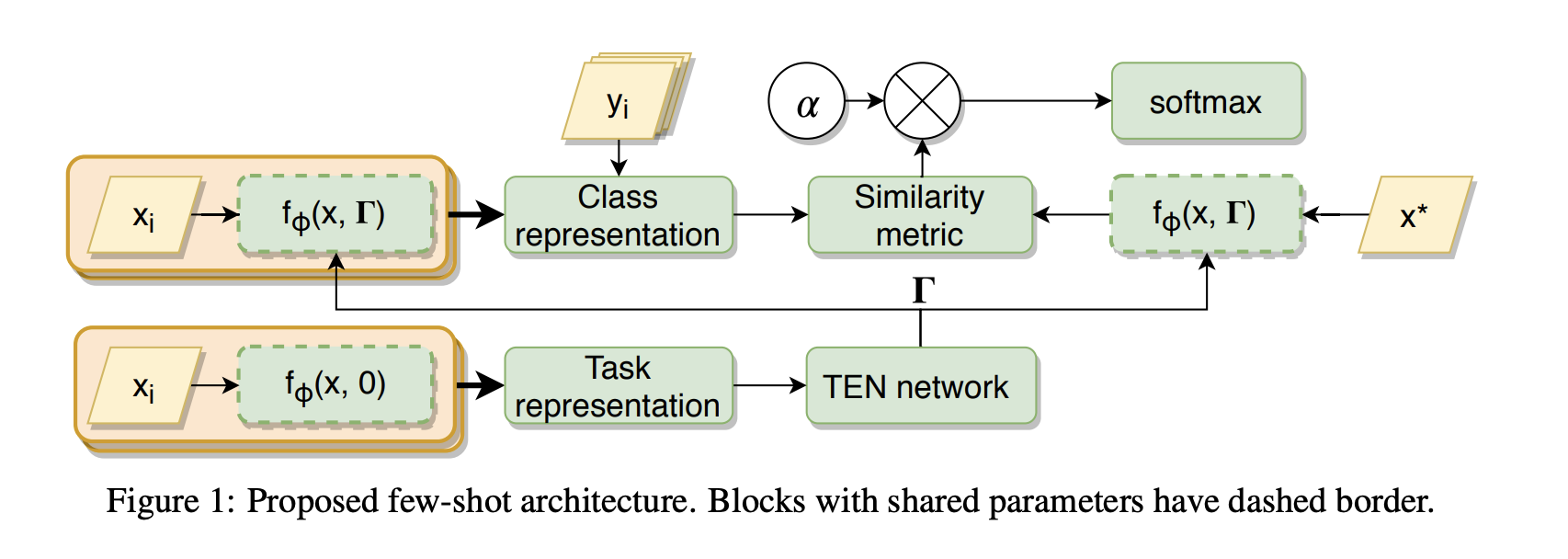
What is meta-learning?¶
Meta-learning (also known as learning to learn) learns sequentially:
Given a series of tasks, it improves the quality of predictions on new (unseen) tasks.
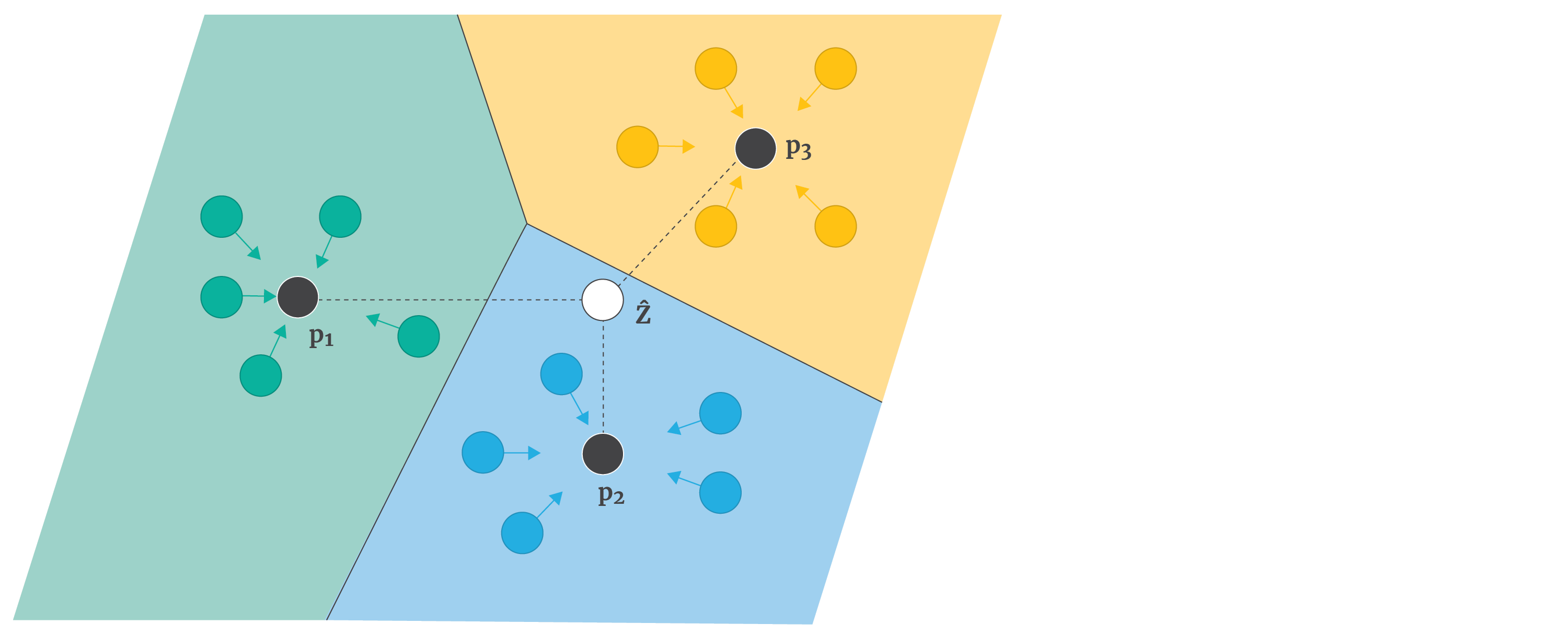
The Meta-learning framework involves training an algorithm using a series of tasks, where each task is a 3-way-2-shot classification problem consisting of a support set with three classes and two examples of each.
During training, the cost function evaluates the algorithm's performance on the query set for each task, given its respective support set.
At test time, a different set of tasks is used to assess the algorithm's performance on the query set, given its support set.
There is no overlap between the classes in the training tasks {cat, lamb, pig}, {dog, shark, lion},
and those in the test task {duck, dolphin, hen}.
As a result, the algorithm must learn to classify image classes generally rather than any particular set.