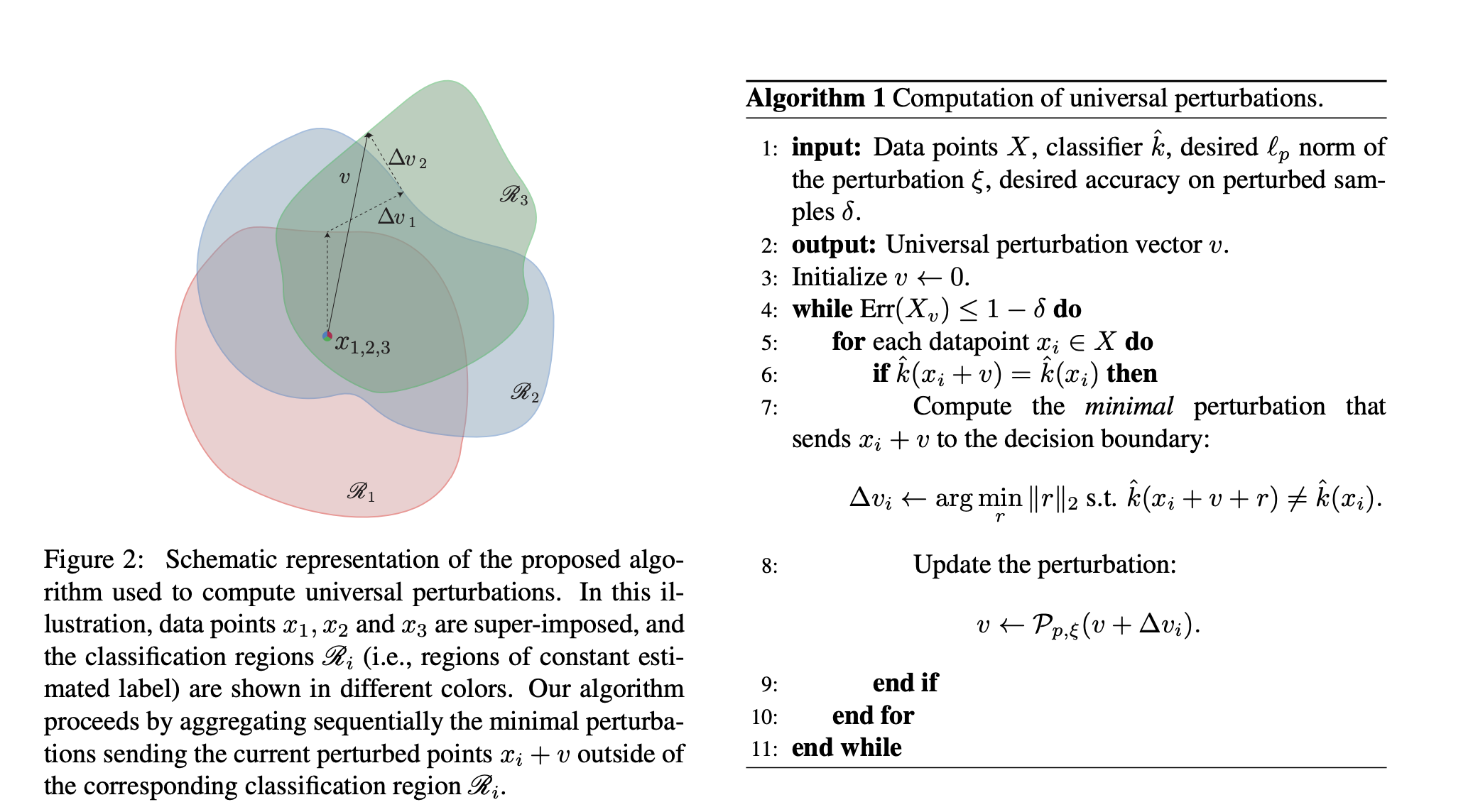
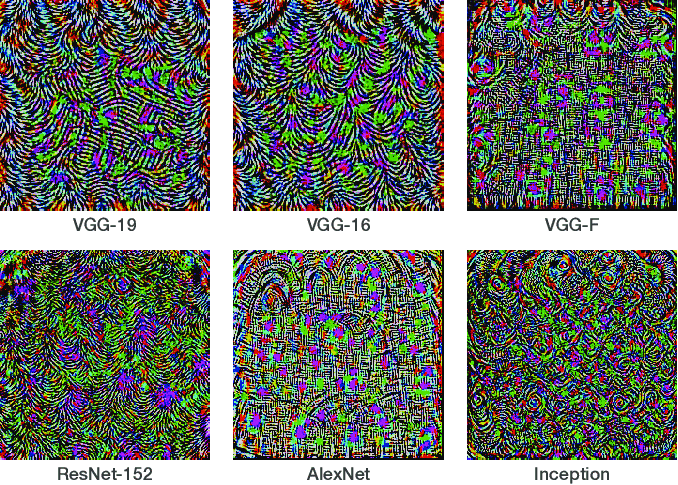
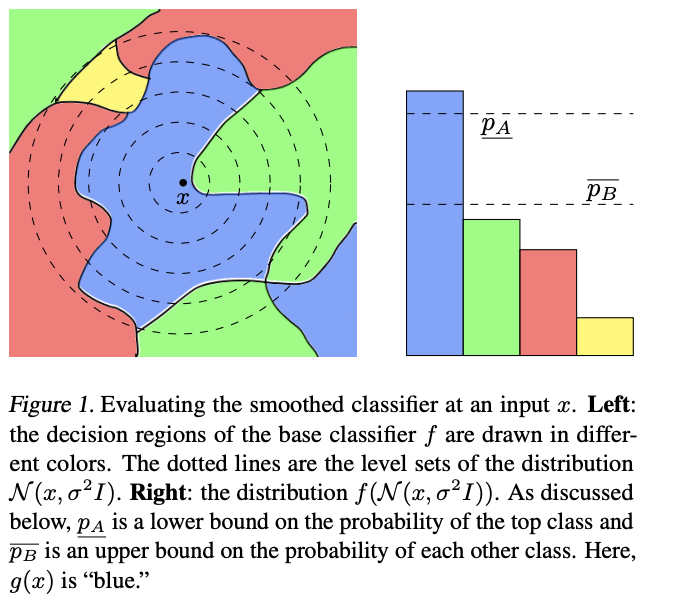
Adversarial attacks: how they were developed.¶
Ian Goodfellow looked at the multiclass classifier, given by the model $p(c \vert x),$ (probability of the class condition at the input).
Suppose we want to move smoothly from one class (cat) to another class (dog).
So, you can just maximize the probability of the image of being a dog, moving in the direction of the gradient
$$\nabla \log p(c_2 \vert x), $$But they found an extremely suprising result: even small modification leads to large missclassification.