Lecture 6: Vision Transformers¶
Previous lecture: Modelling sequences¶
- Modelling sequences
- Recurrent neural networks (RNN) and their variants: RNN, GRU, LSTM
- Concept of attention
- Transformer architecture
Todays lecture¶
- Original idea of VIT
- Beit (3 versions)
- Cait
- Cross-ViT
- SWIN
- Transformers for object detection
- DINO
- MobileVIT (3 versions)
- XCiT
- MLP-Mixer
Transformers in vision¶
Transormer-based models have revolutionized NLP models. The idea to apply them to images seems to be natural --- only after it has been proposed in the paper
What is the main idea?
Patches¶
The main task is to replace an image by a sequence.
The most natural idea to do so is patches.
The image is split into patches (blocks). The blocks are processed by a very simple 1-layer convolutional neural networks,
the patches are flattened and positional encodings are added to each pixel.
For classification, and additional classification head is added.
It is better to see...

Architecture of VIT¶
When we have our sequence, we can just apply the transformer on top to do classication.
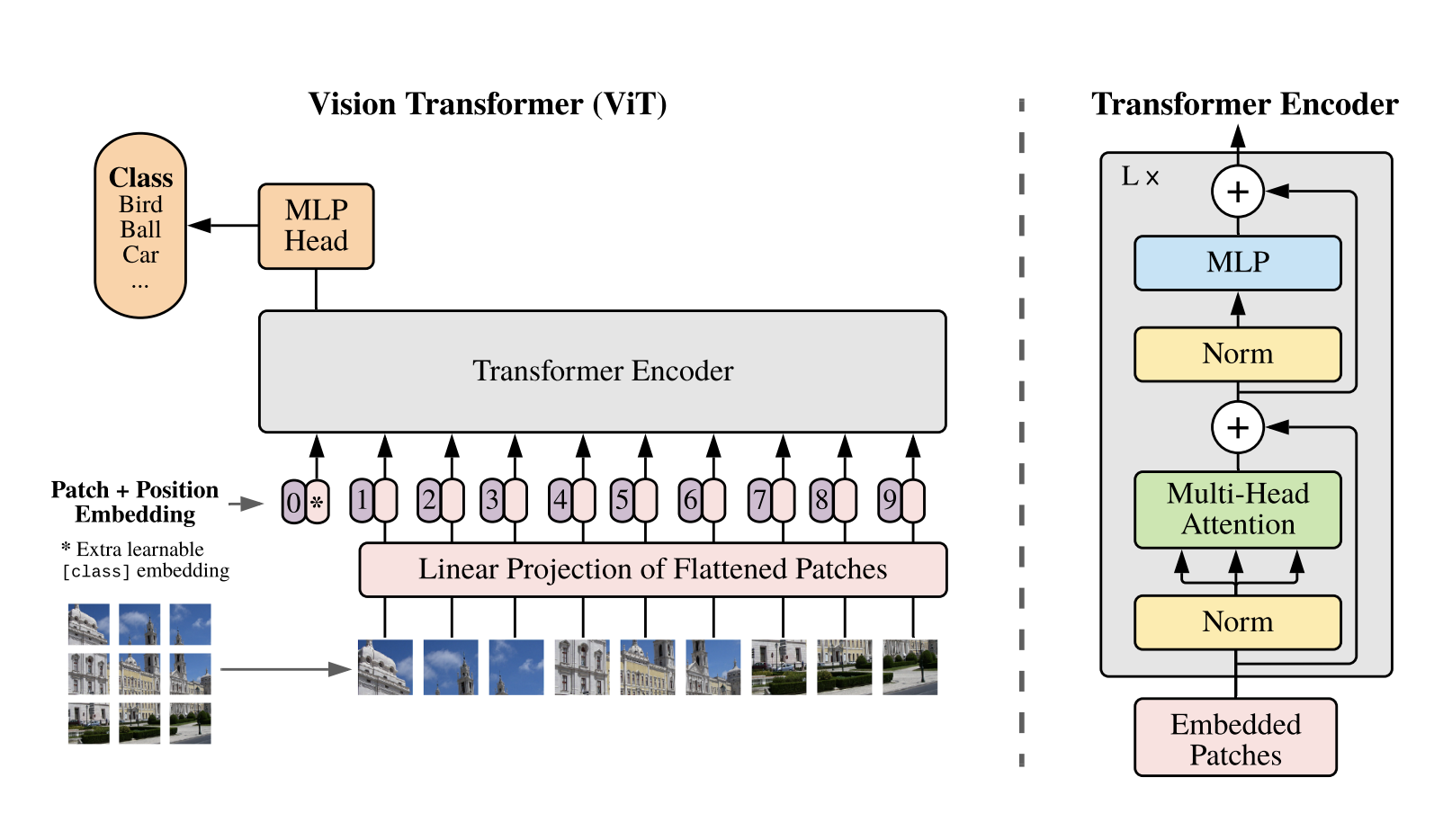
General scheme of VIT¶
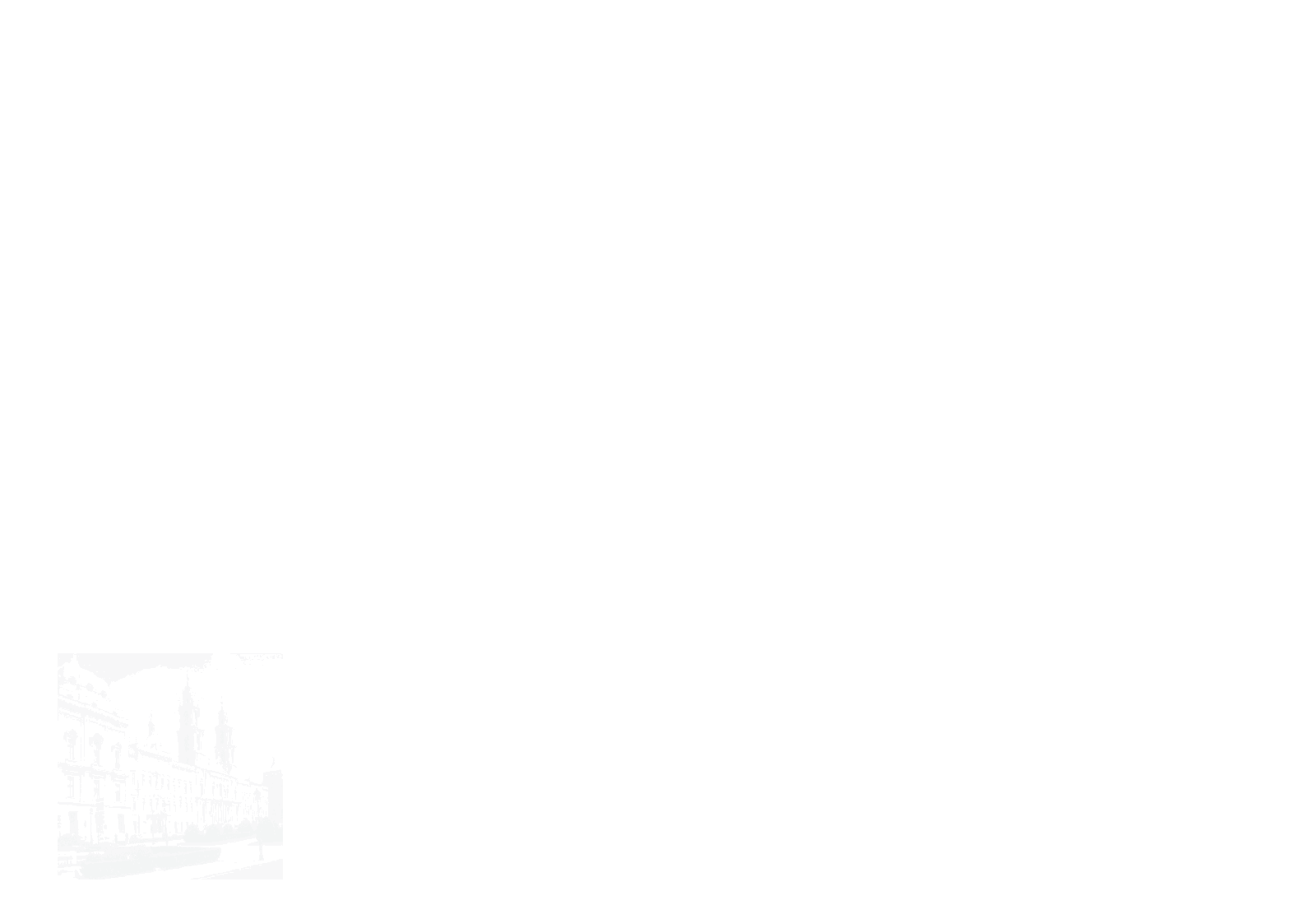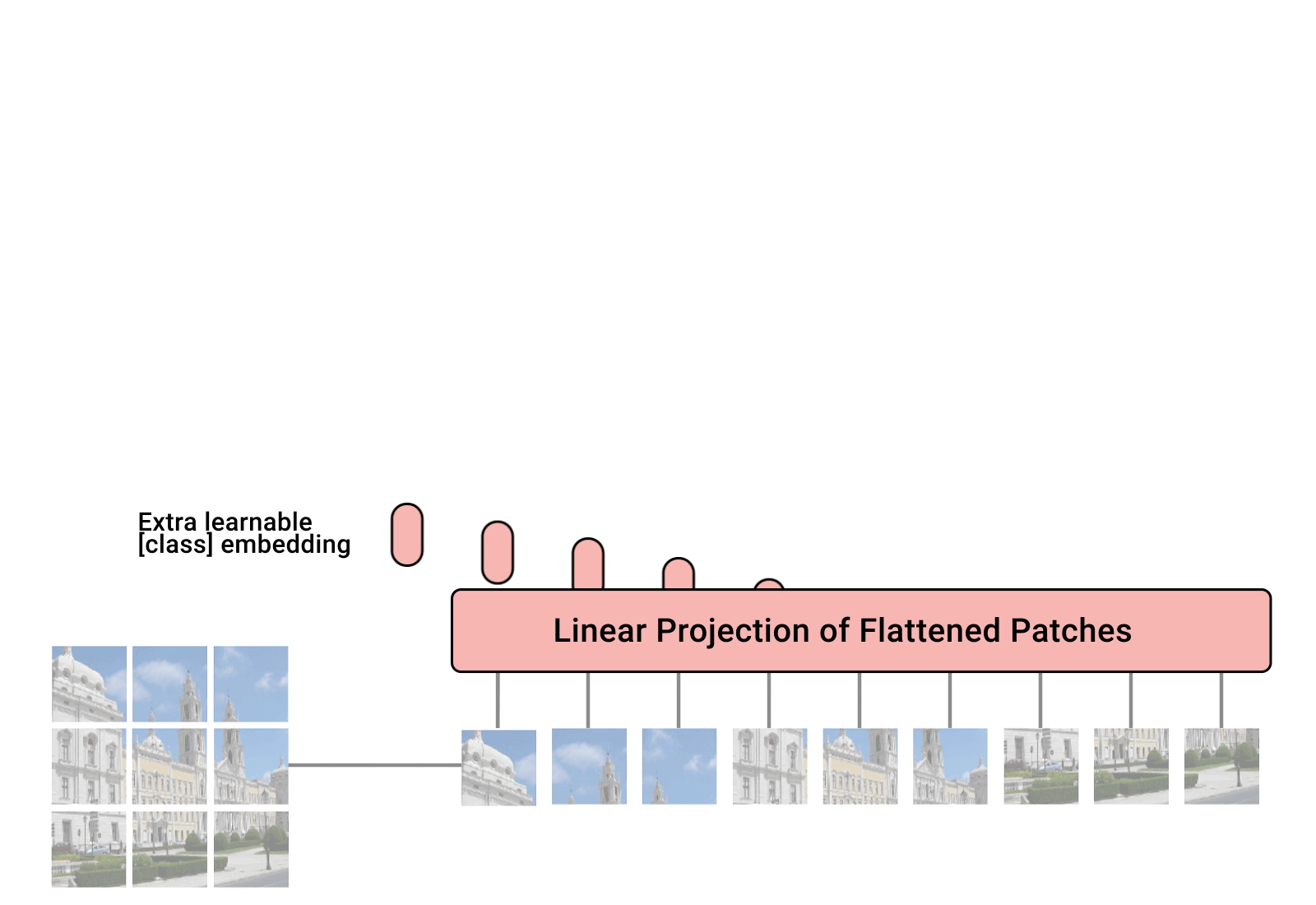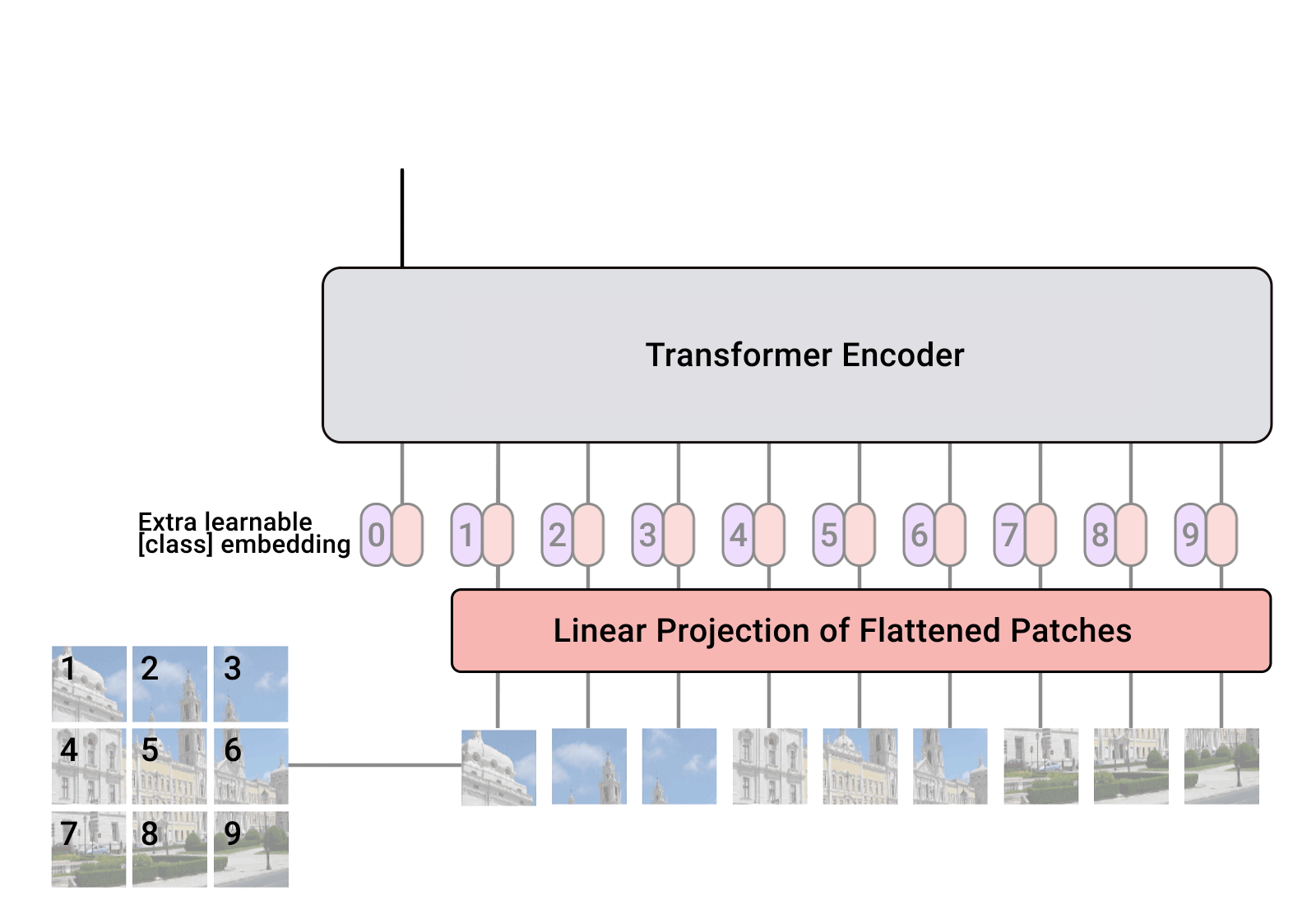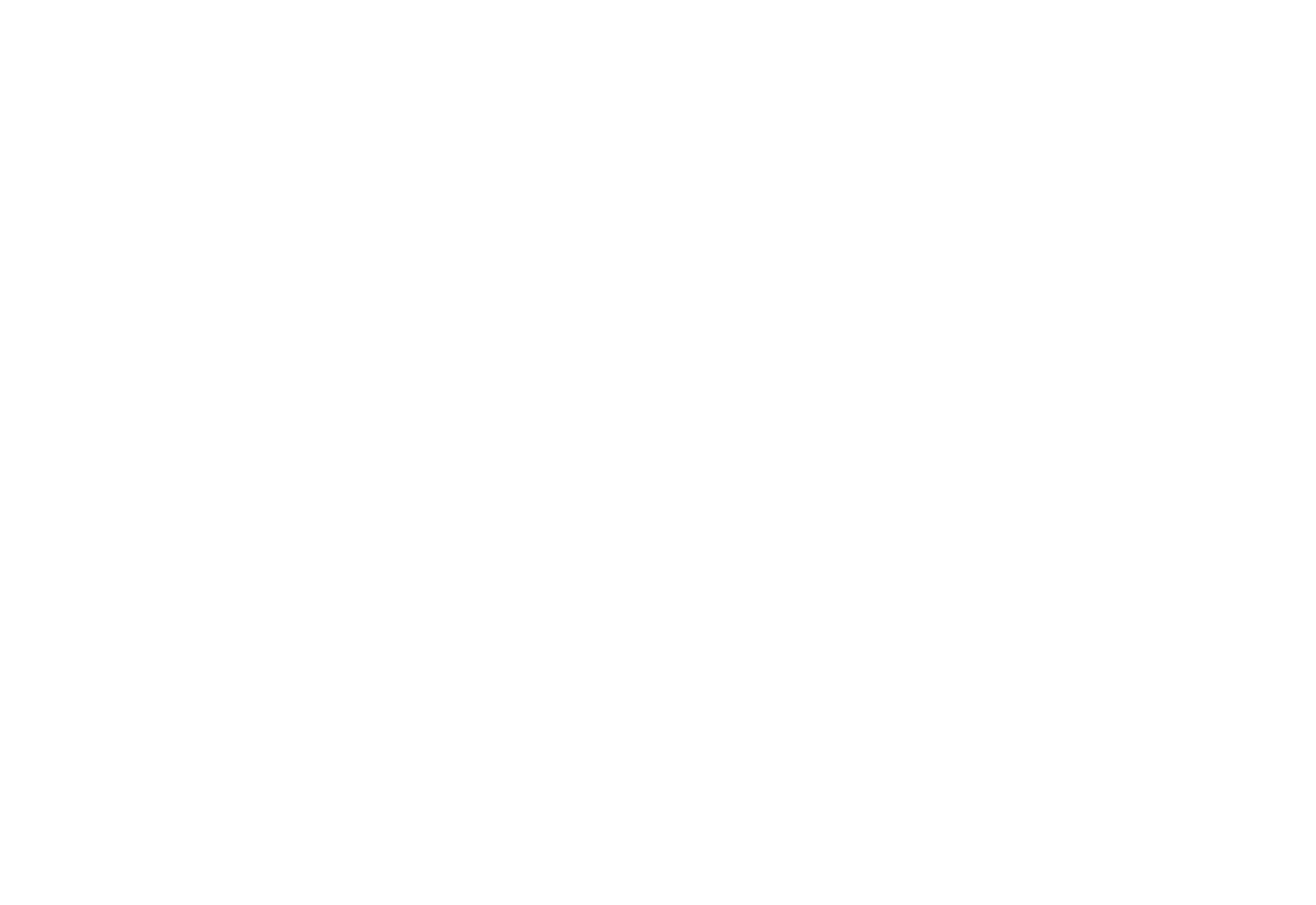
Training original VIT¶
The model is pretrained on large datasets and then fine-tuned on downstream tasks.
Position embeddings are learnable.
Training on downstream tasks¶
For training on downstream tasks, the prediction head for the original classification task is removed and replaced by $D \times K$ layer where $K$ is the number of output classes.
We can also train on higher resolution. How can we train on a higher resolution?
Training on higher resolution¶
Fully-convolutional neural networks and be applied to arbitrary resolution images.
VIT can also be applied to images of arbitrary resolutions.
The patch size is the same, thus different resolution will lead to larger sequence lengths, and transformer can be applied to sequences of variable length.
The only small problem is positional encodings, but they can be interpolated for new image sizes.
Types of original VIT models¶
The original VIT models differ in the sizes of the layers and number of them
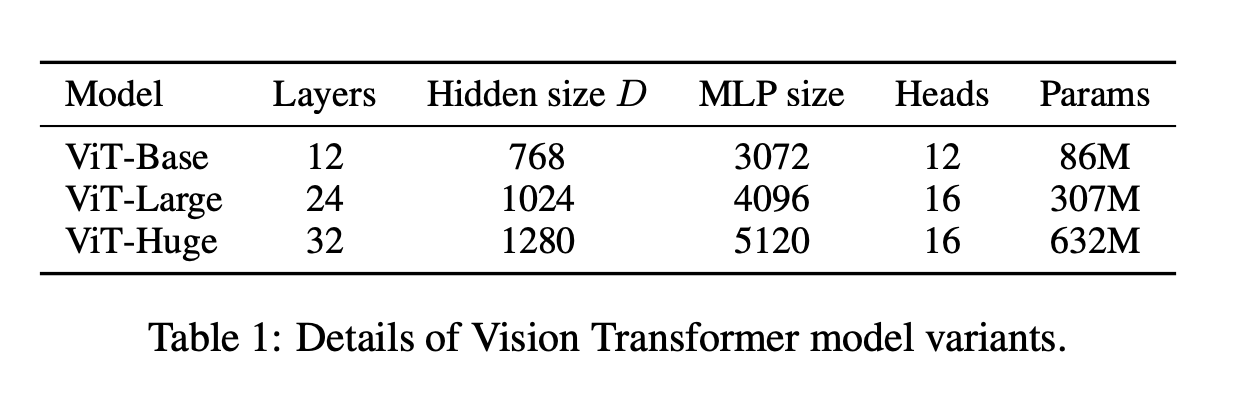
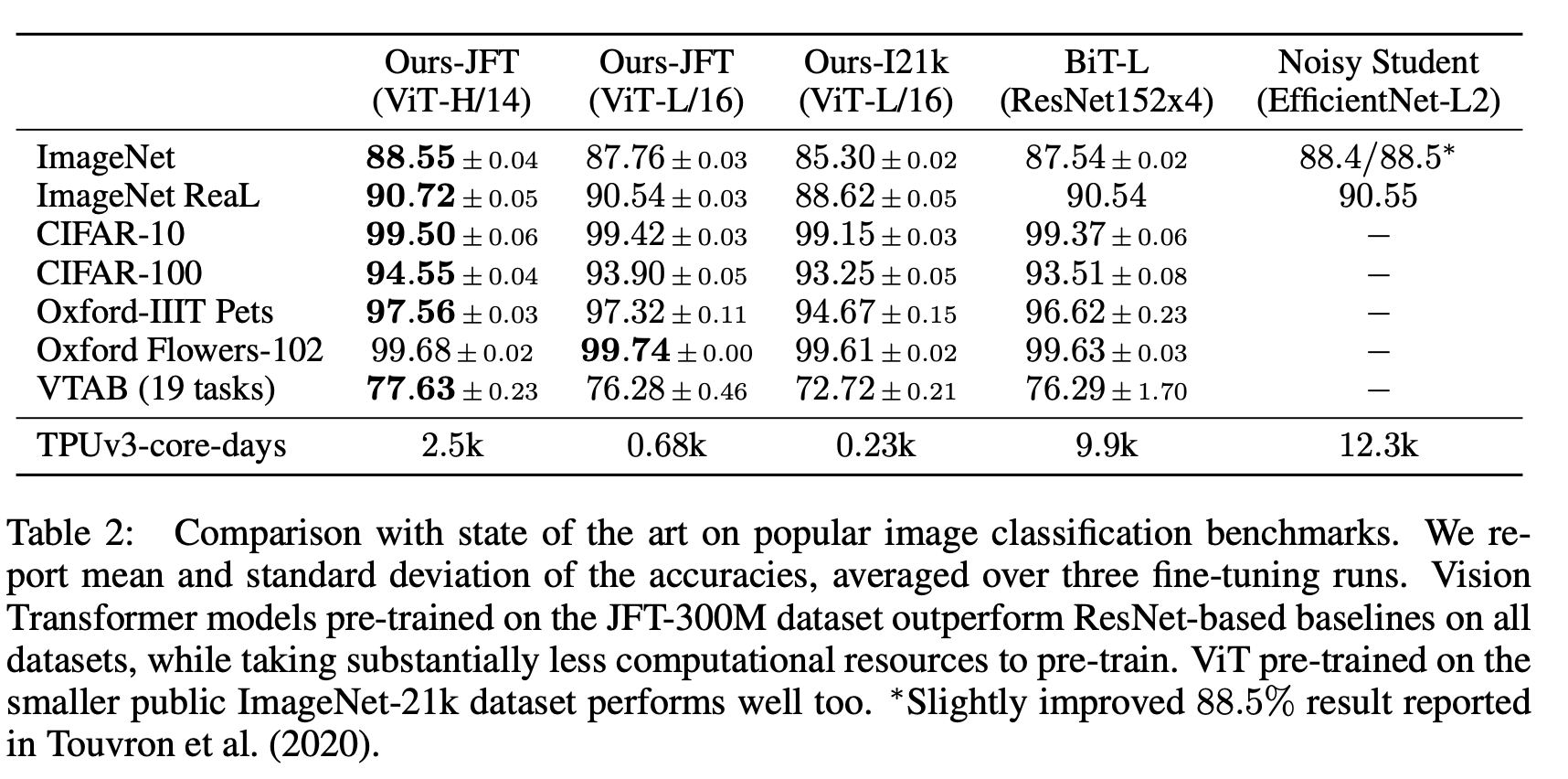
VIT-numbers¶
The numbers from the original VIT paper compared with ResNet baselines.
The JFT dataset has 303M images, I21K (Imagenet 21k) has 14M images.
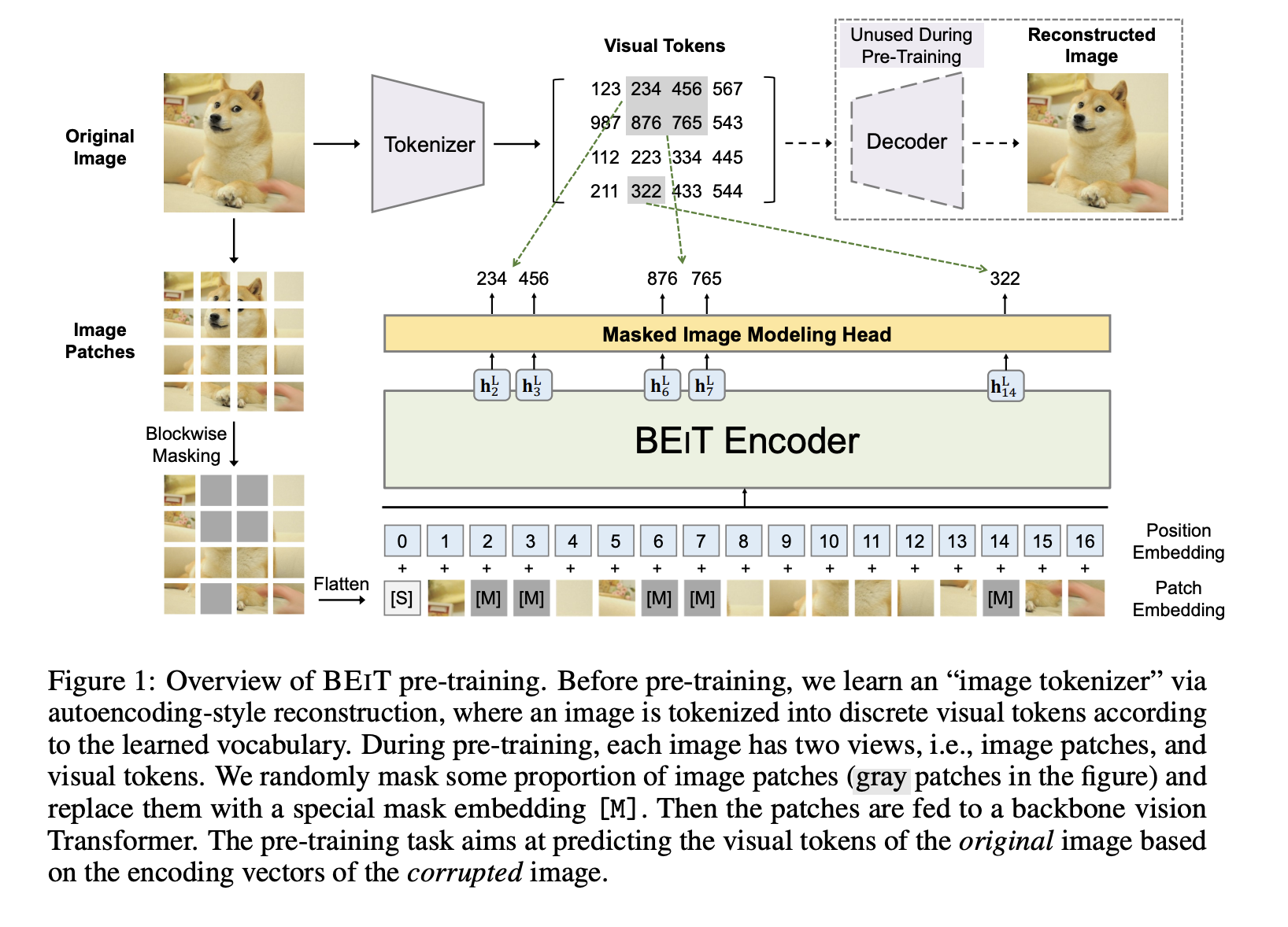
Self-supervised pre-training¶
One can also do self-supervised pretraining: similar to BERT, we can mask some of the patches and try to reconstruct them.
The original VIT paper reported 79.9% accuracy on ImageNet (2% more compared to training from scratch, but 4% less behind supervised pretraing.
This was later explicitly done in BEiT: BERT Pre-Training of Image Transformers
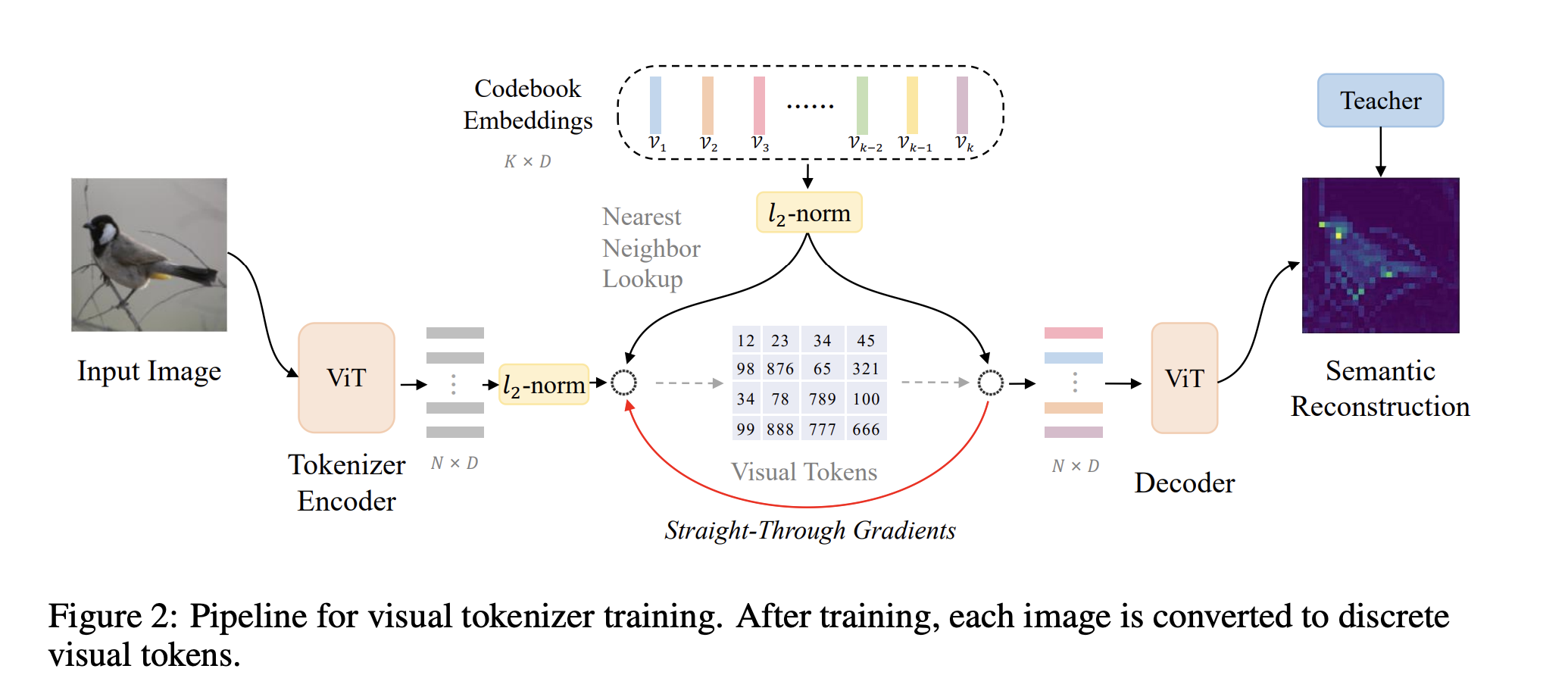
Bert pretraining of image transformers¶
The image has two views: patches and visual tokens. The visual tokens are highly non-trivial: they are based on latent codes of discrete variational autoencoders
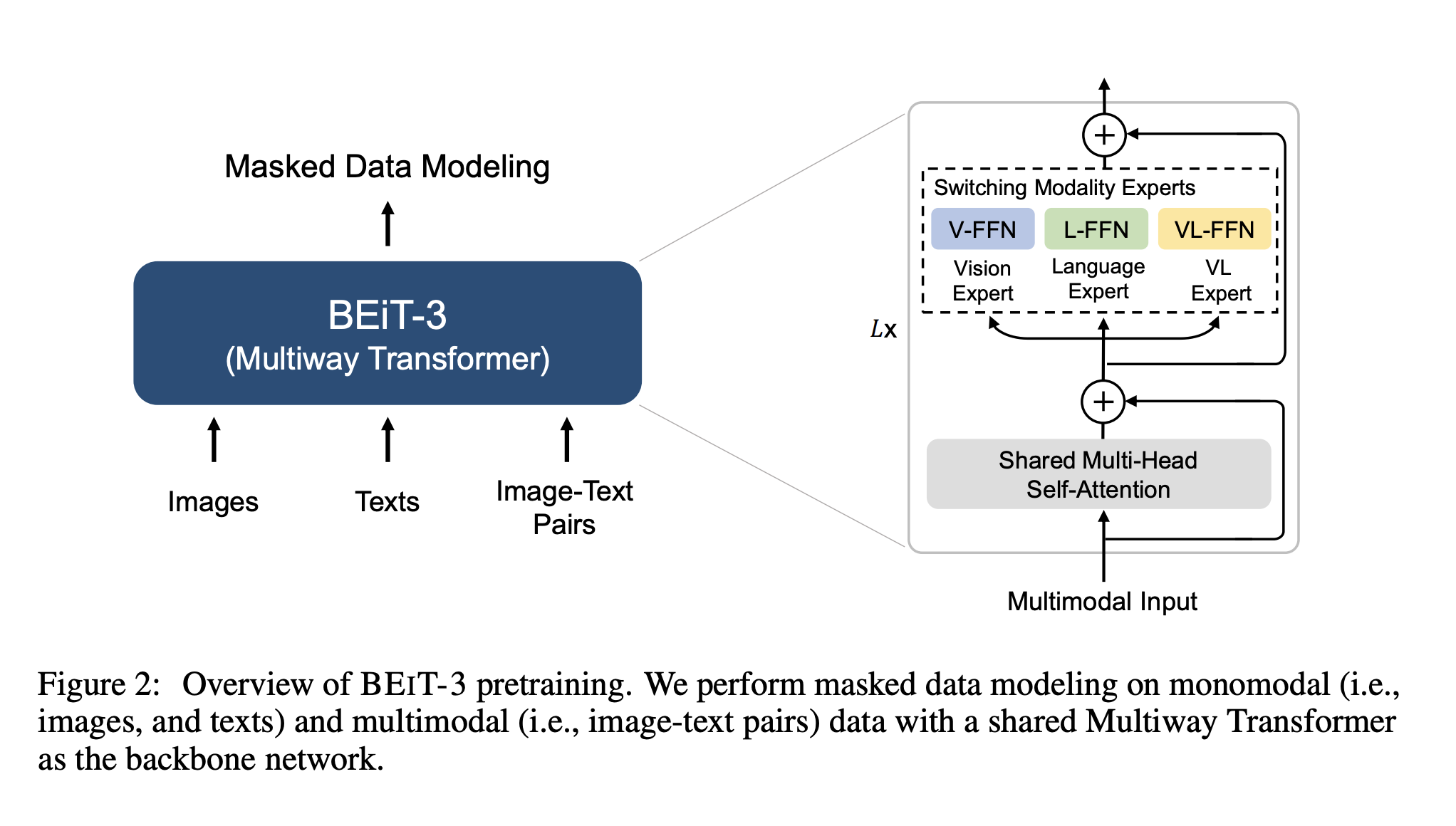
BeIT version 3¶
Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks has reached SOTA on many classical tasks:
- object detection (COCO)
- semantic segmentation (ADE20K)
- image classification (ImageNet)
- visual reasoning (NLVR2)
- visual question answering (VQAv2)
- image captioning (COCO)
- cross-modal retrieval (Flickr30K, COCO).
The idea is to use masked pretraining!
DEIT transformer¶
The next milestone is data-efficient image transformer (DeIT) proposed in Training data-efficient image transformers & distillation through attention
One of the conclusions of VIT paper was that vision transformers do not generalize well when trained on insufficient amount of data which is not true
The DEIT paper showed that transformers can be trained competitively on the same data.
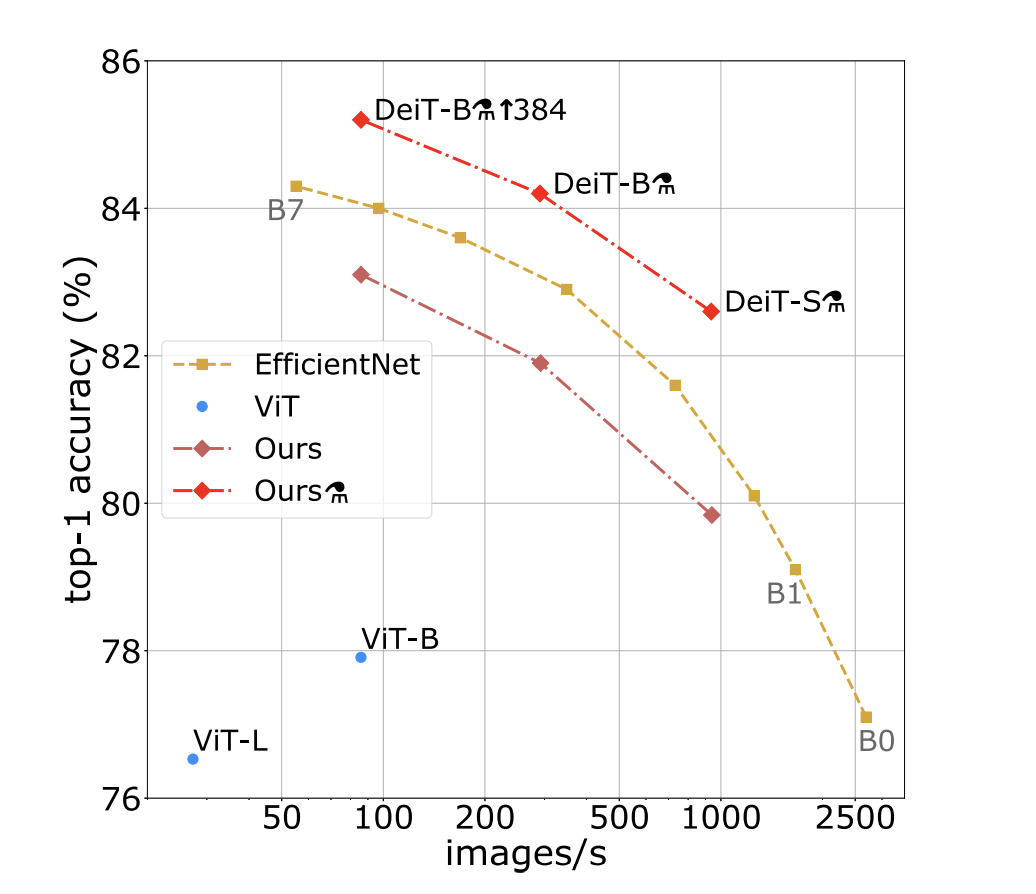
DEIT training efficiency¶
The model is trained on ImageNet, Deit-B has the same architecture as VIT-B but in data-starving regime, trained on several days on one node with 4 GPUs.
The training had several innovations and tricks, and the most interesting part: distillation (learning from another neural network).
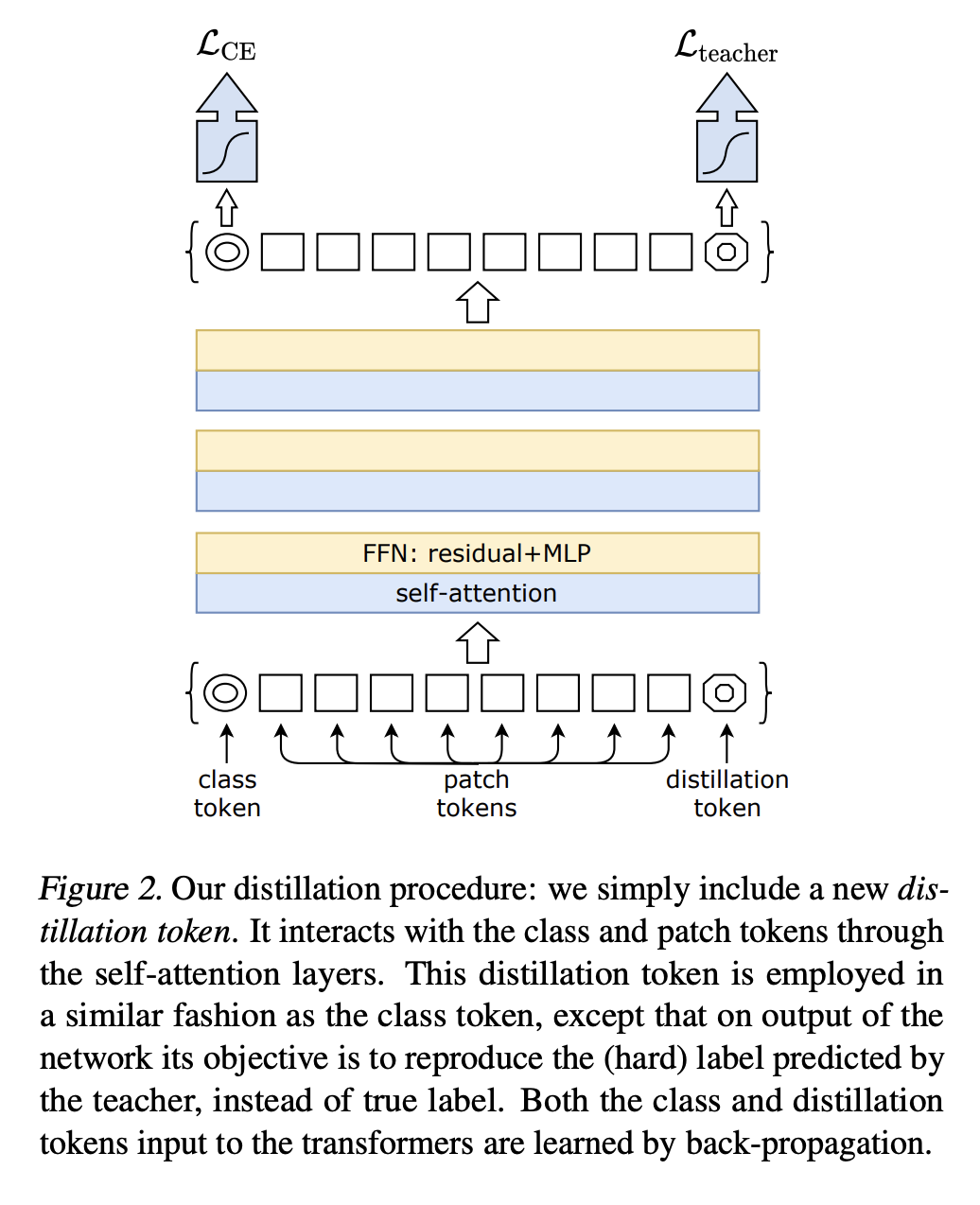
Distillation¶
We have one model $f_1(x)$ (called teacher), and we want that another model (student) learns from such predictions.
The idea of DeIT paper (and it seems to be the main contribution of it) is the idea of distillation through attention.
CaIT transformer¶
Another innovation from the same group Going deeper with Image Transformers proposes the architectural modifications:
- Put class token deeper into the architecture
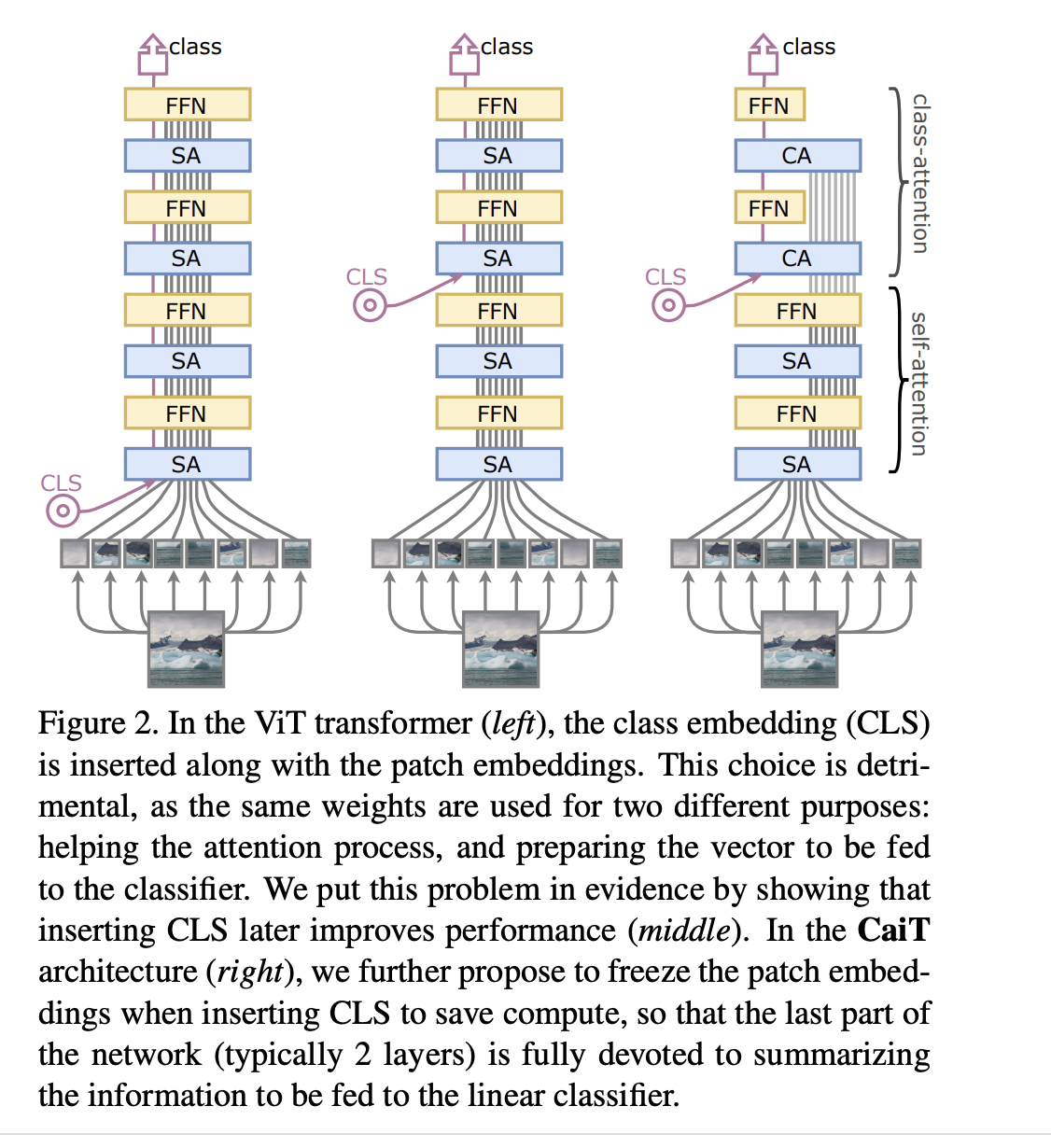 - **LayerScale:** in the residual connection, the weights are multiplied by very small numbers at initialization (starting layers are almost identical). These numbers are **learnable**.
- **LayerScale:** in the residual connection, the weights are multiplied by very small numbers at initialization (starting layers are almost identical). These numbers are **learnable**.
$$x'_l = x_l + \mathrm{diag}(\lambda_{l,1}, \ldots, \lambda_{l, d}) \mathrm{SA}(\eta(x_l)).$$
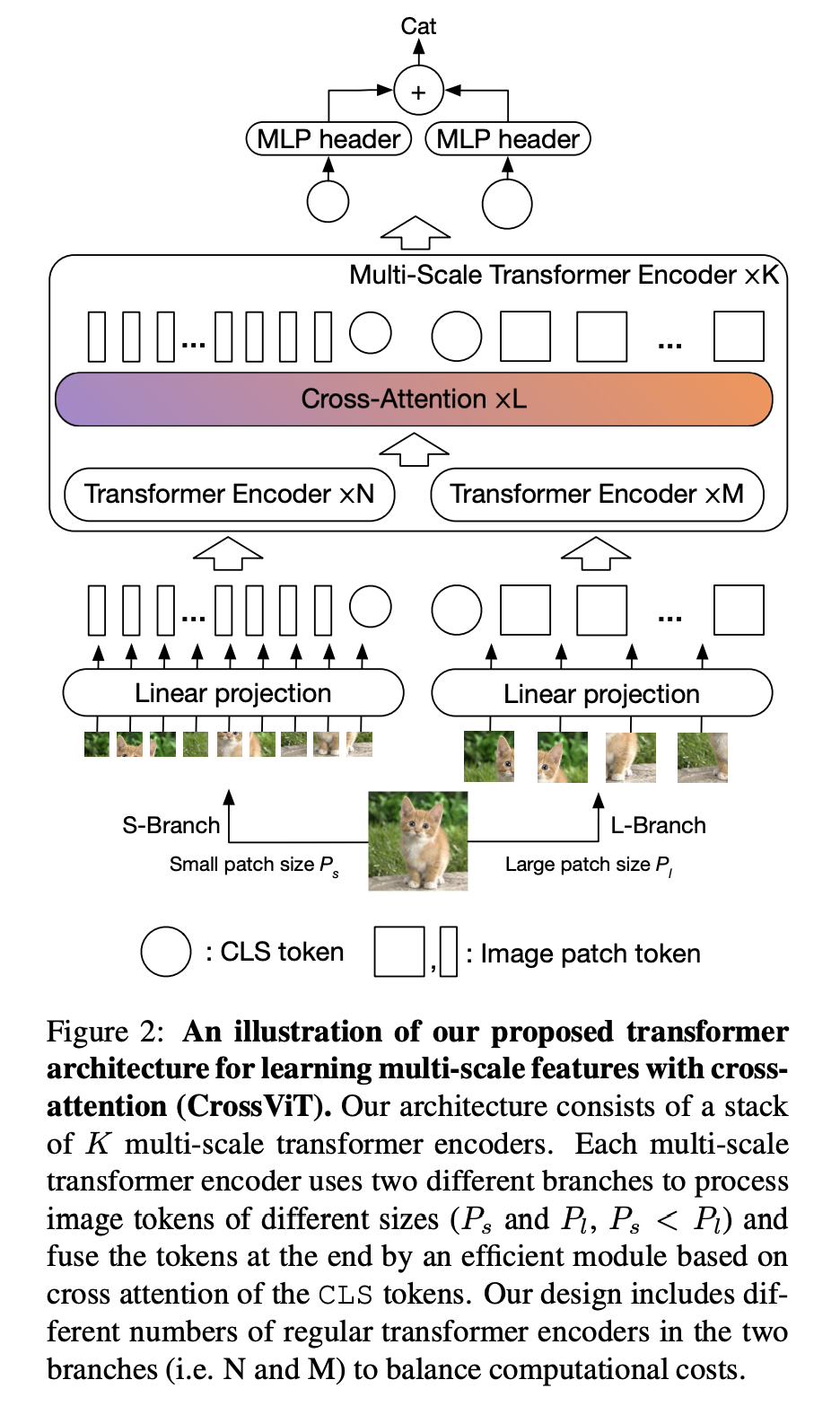
Cross-VIT: yet another attention¶
Cross-VIT paper proposes a multiscale variant (later to be replaced with so-called SWIN transformer which we will discuss later).
The idea is to process patches of different sizes.
This can be done by parallel branches. But how can we exchange information between those branches?
Cross-VIT: scheme¶
The Cross-VIT comes from cross-attention, the concept we have not yet discussed.
It is attention between two different token sets (compared to self-attention).
SWIN transformer¶
Next architecture step is Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, ICCV 2021
Challenge 1: One of the main differences between NLP and CV is scale: different objects have different sizes.
In VIT, all tokens have the same size.
Challenge 2: The token size. If we go to higher resolutions, the self-attention will scale quadratically with the number of tokens (patches), making computations infeasible.
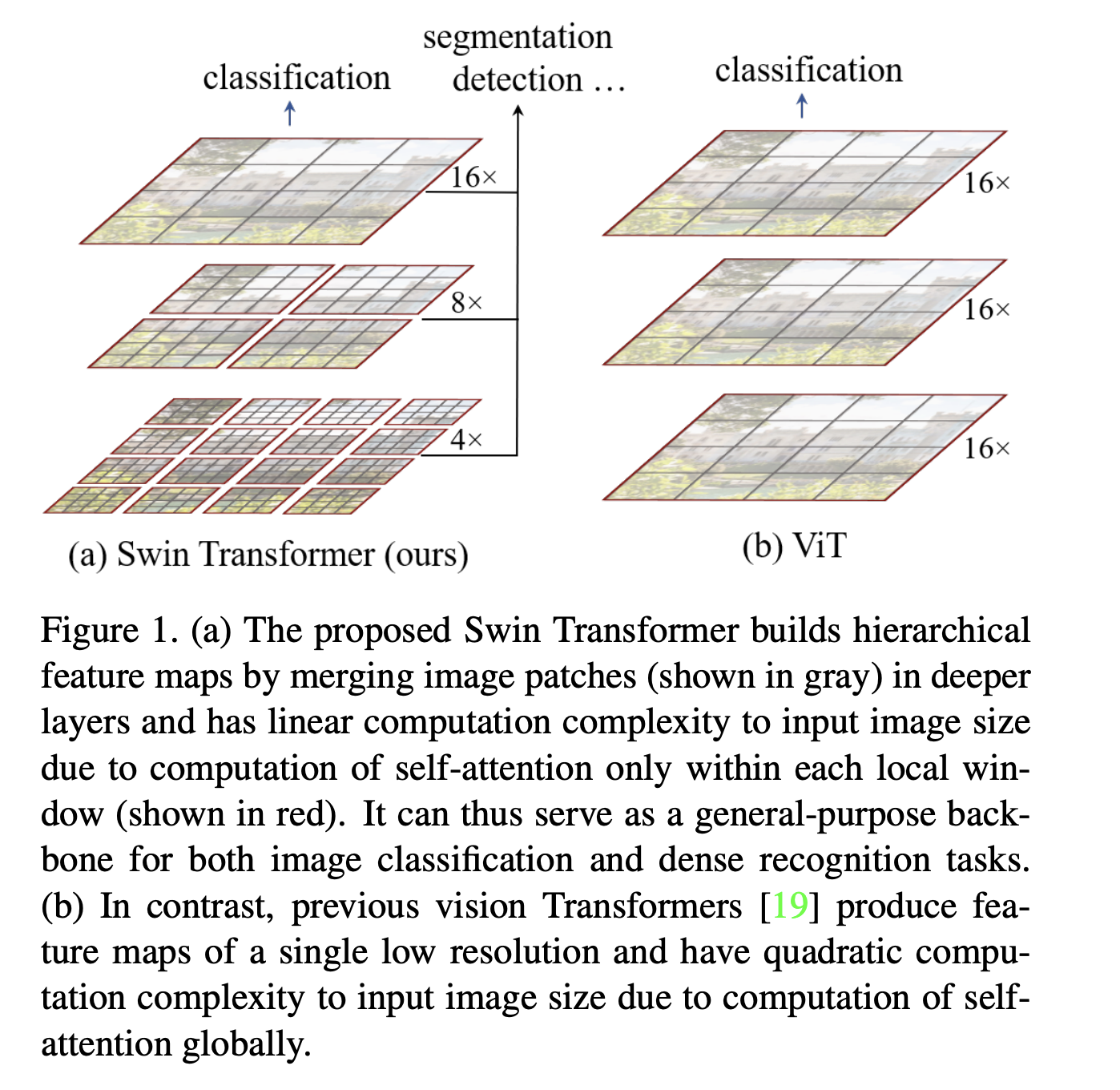
SWIN-scheme of the model¶
The model has the following scheme (from the original paper). The main difference is in self-attention: it is only computed in local windows, removing the quadratic complexity effectively.
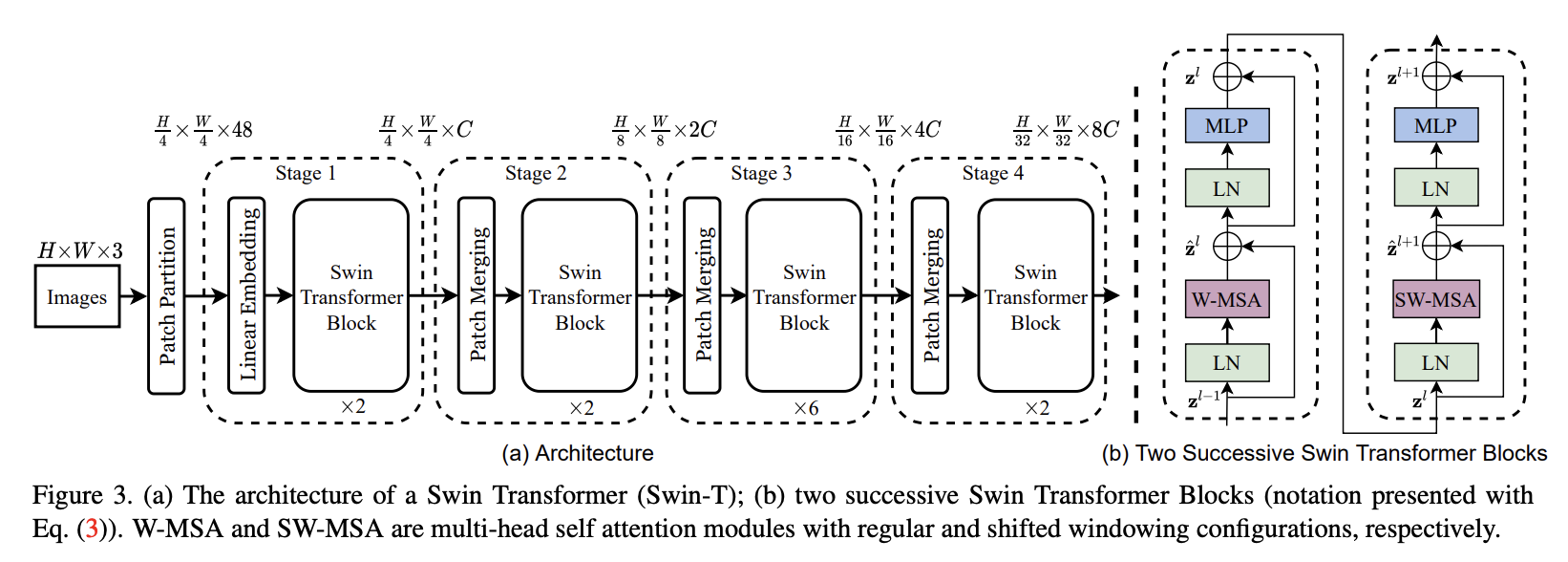
Two self-attention modules in SWIN¶
SWIN transformer has two different attention.
First is W-MSA (window multi-head self-attention), where attention is computed within a local window.
Second is SW-MSA (shifted window multi-head self-attention), where attention is computed within a window shifted by half-of-the size).
Architecture variants¶
The variants considered in the original paper:
$ \text{Swin-T}: C = 96, \text{layer numbers} = \{2, 2, 6, 2\} $
$ \text{Swin-S}: C = 96, \text{layer numbers} = \{2, 2, 18, 2\} $
$ \text{Swin-B}: C = 128, \text{layer numbers} = \{2, 2, 18, 2\} $
$ \text{Swin-L}: C = 192, \text{layer numbers} = \{2, 2, 18, 2\} $
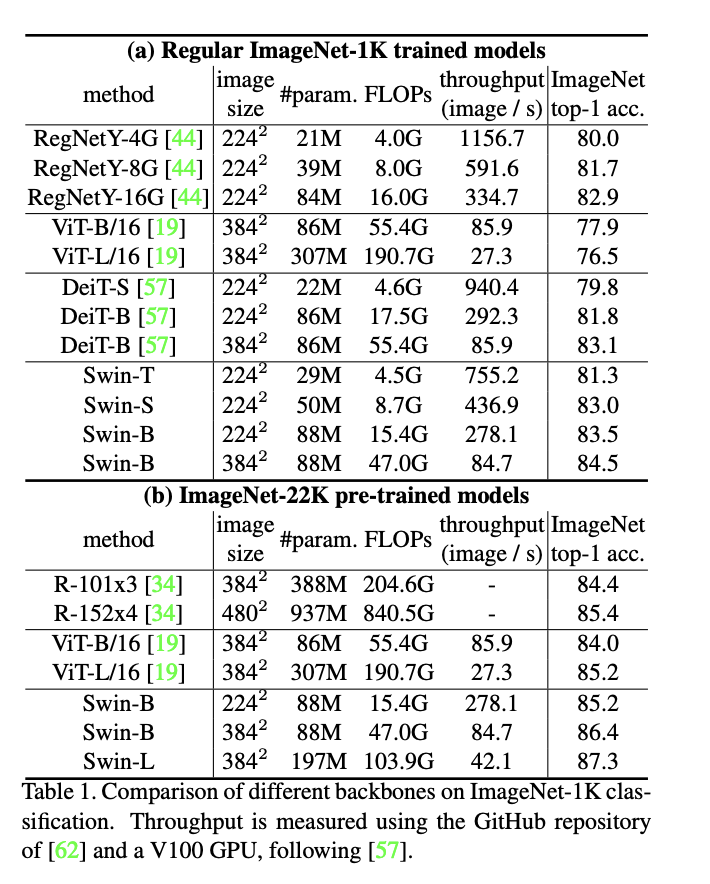
Transformer for other tasks¶
One can directly change the backbone from CNN to SWIN and leave everything 'as it is'.
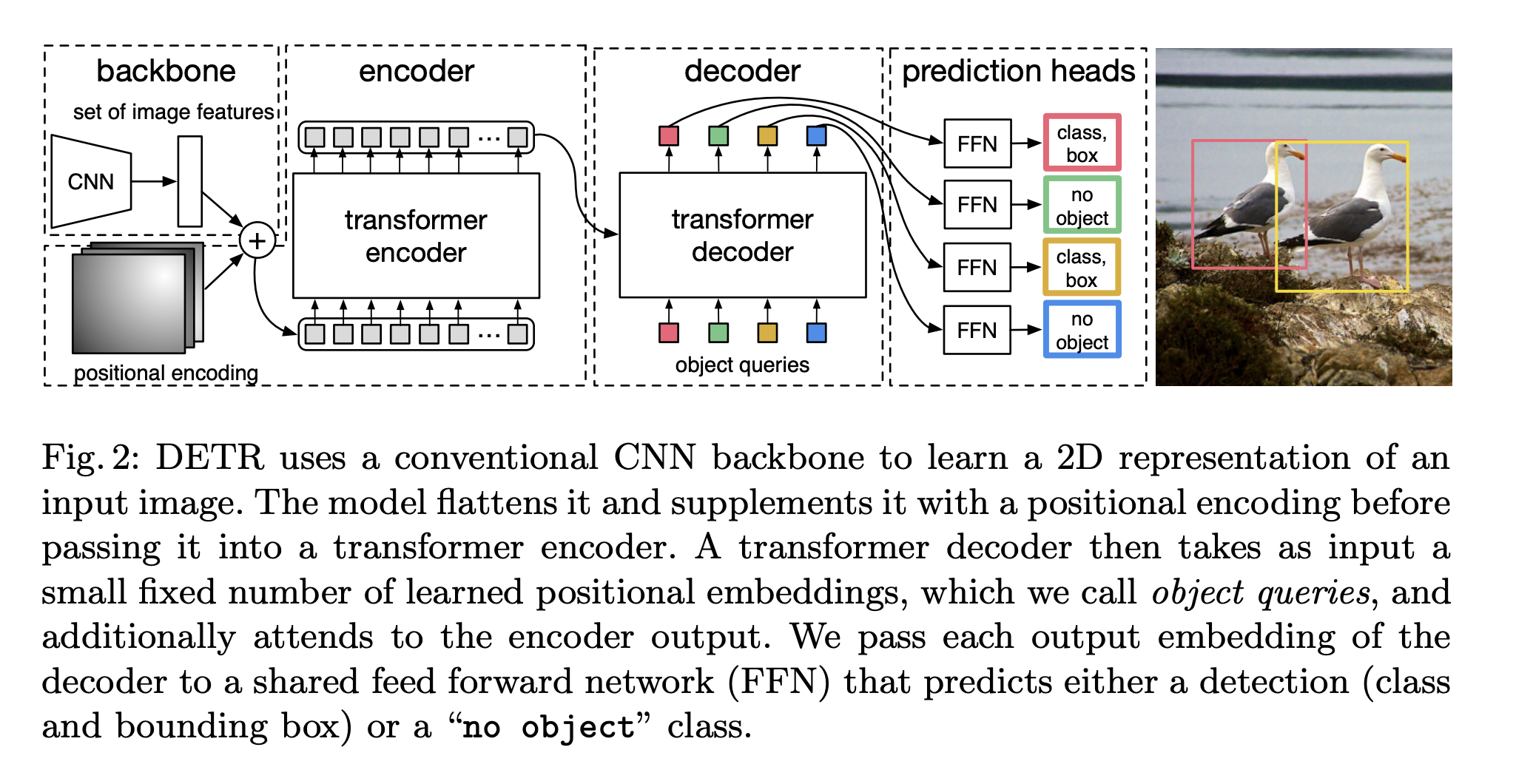
End-to-end detection with transformers: loss¶
The first application of transformers was in End-to-End Object Detection with Transformers.
Which proposed DEtection TRansformer (DETR) architecture.
Let us denote by $y$ the ground truth set of objects, $\hat{y} = \{\hat{y}_i\}_{i=1}^N$ the set of predictions.
Then, we match the sets
$$\hat{\sigma} = \arg \min_{\sigma \in \Pi_N} \sum_{i=1}^N \mathcal{L}_{\mathrm{match}}(y_i, \hat{y}_{\sigma_i})$$The optimal matching can be computed by i.e. Hungarian algorithm (optimal assignment problem).
For the matching selected, the loss is computed.
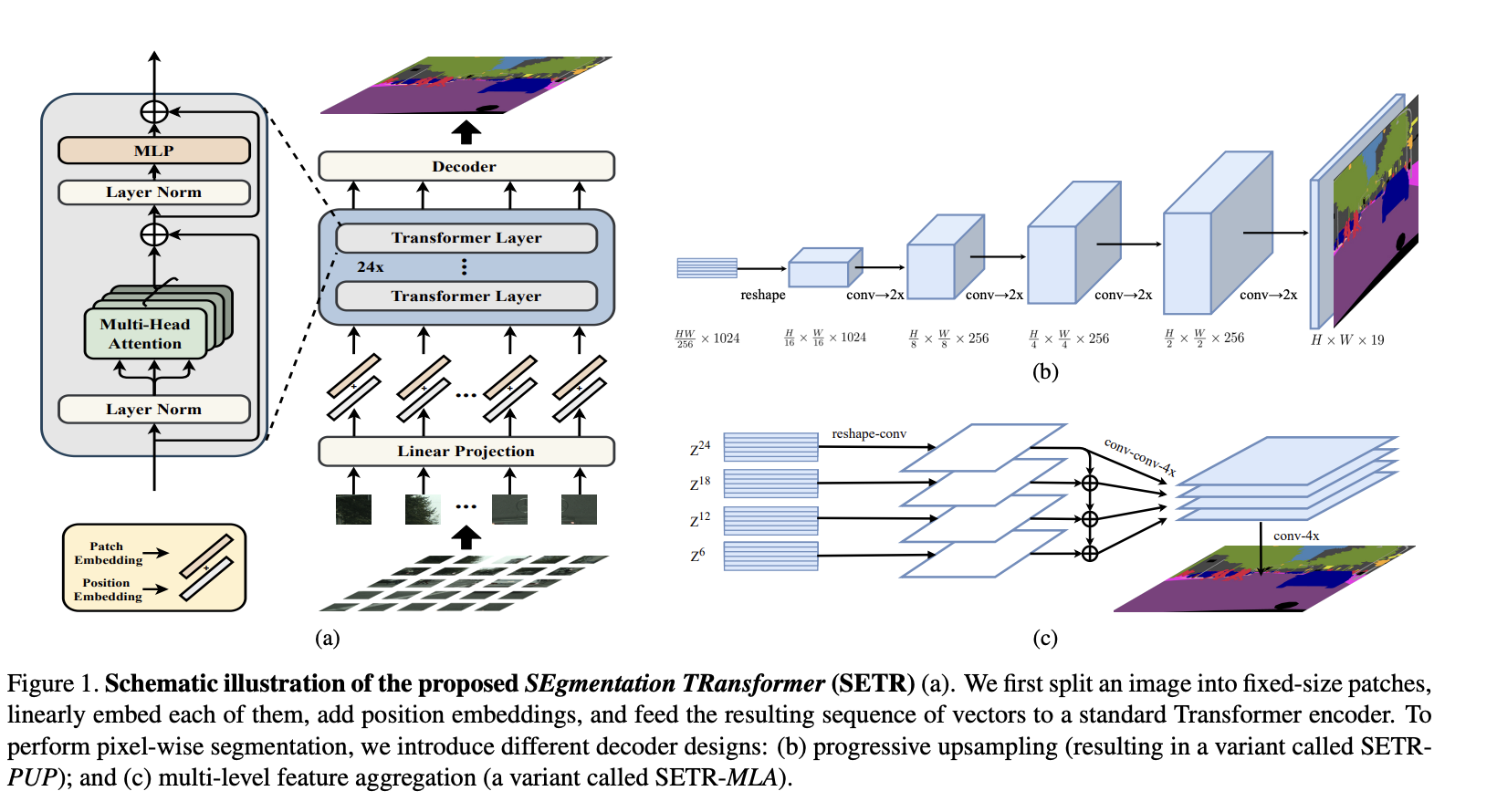
Semantic segmentation with transformers¶
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Building upon idea of of fully-connected-networks, we can design a transformer-based architecture for segmentation.
DINO¶
Distillation with No labels: self-supervised contrastive learning.
Replaces masking with training on image augmentations.
You can also learn meaningful embeddings with masked autoencoders see Masked Autoencoders are scalable vision learners
How and why it is done we will cover in the corresponding lecture.
Now we can move to making transformers more efficient.
Mobile versions: MobileVIT¶
VIT-B version is much heavier:
ViT-B/16 vs. MobileNetv3: 86 vs. 7.5 million parameters
Seem to be more difficult to optimize.
Paper MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer proposes a light-weight architecture for transformers.
Key idea of MobileVIT¶
The key idea of MobileVIT is leave the spatial structure of the patches.
I.e., we have
- Convolutions
- Transformer on patches (no flattening of patches!)
Architecture of Mobile-VIT¶
The full architecture of original MobileVIT (compared to VIT) is shown here:
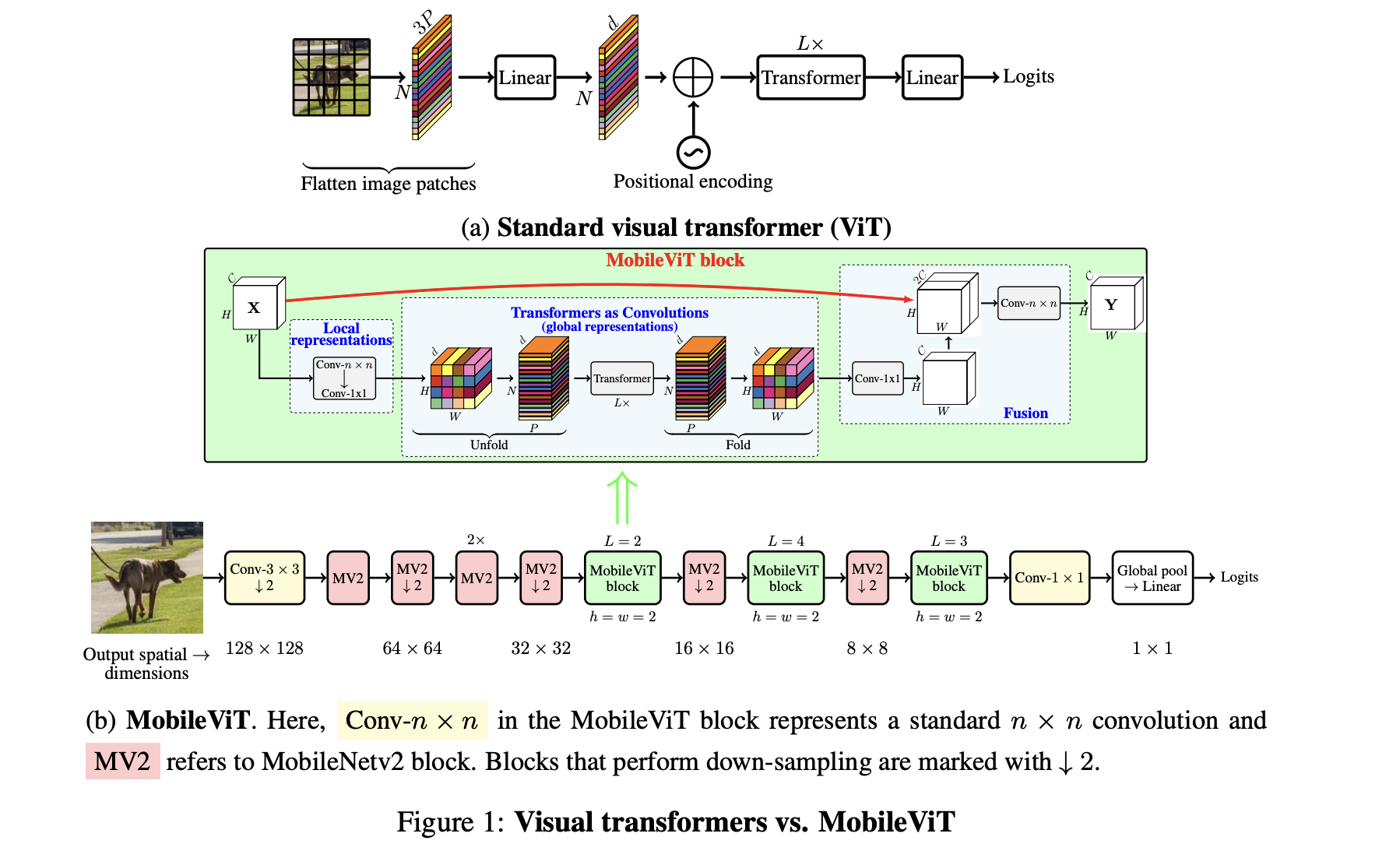
Numbers of original MobileVIT¶

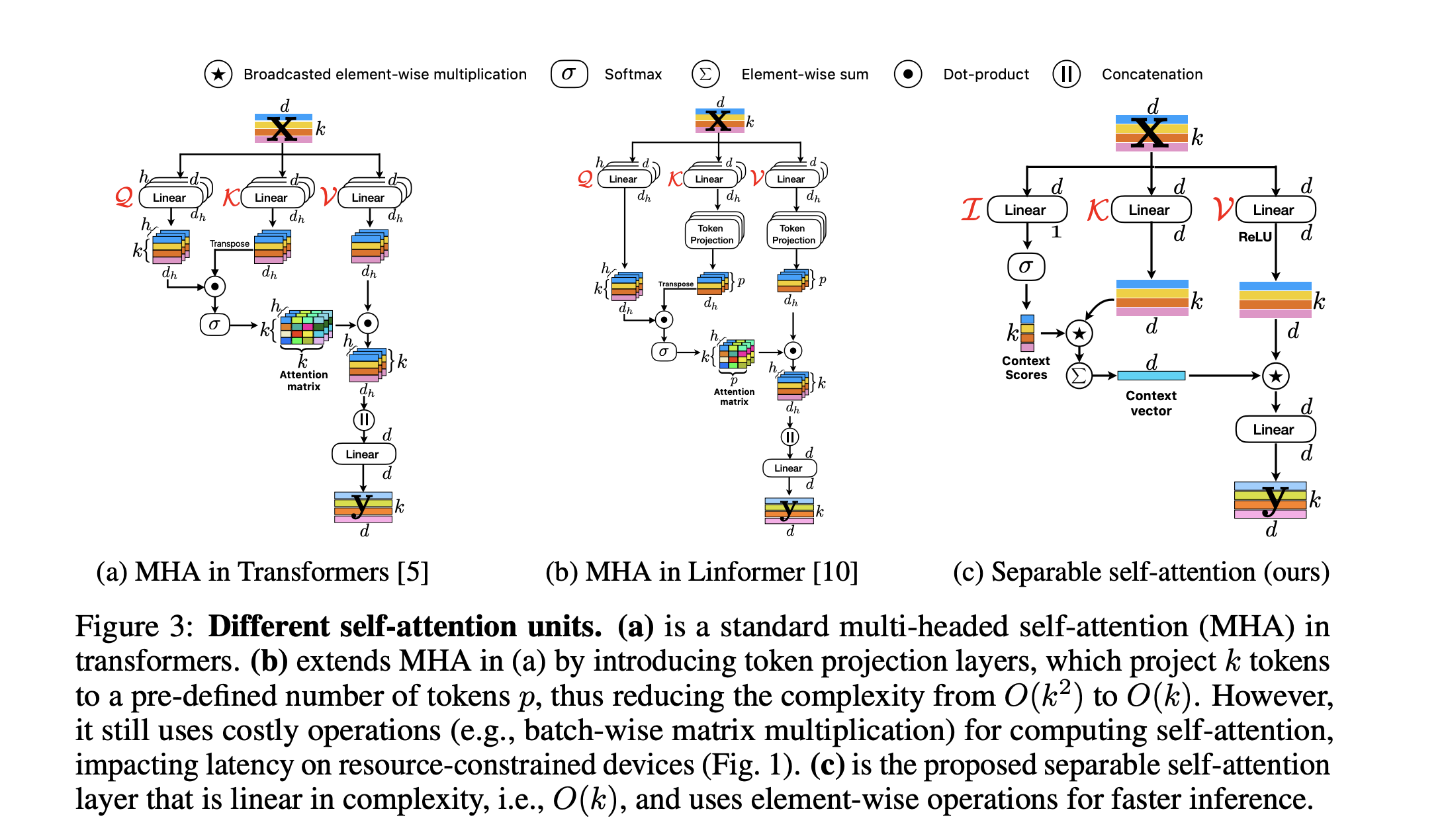
MobileVIT-version3¶
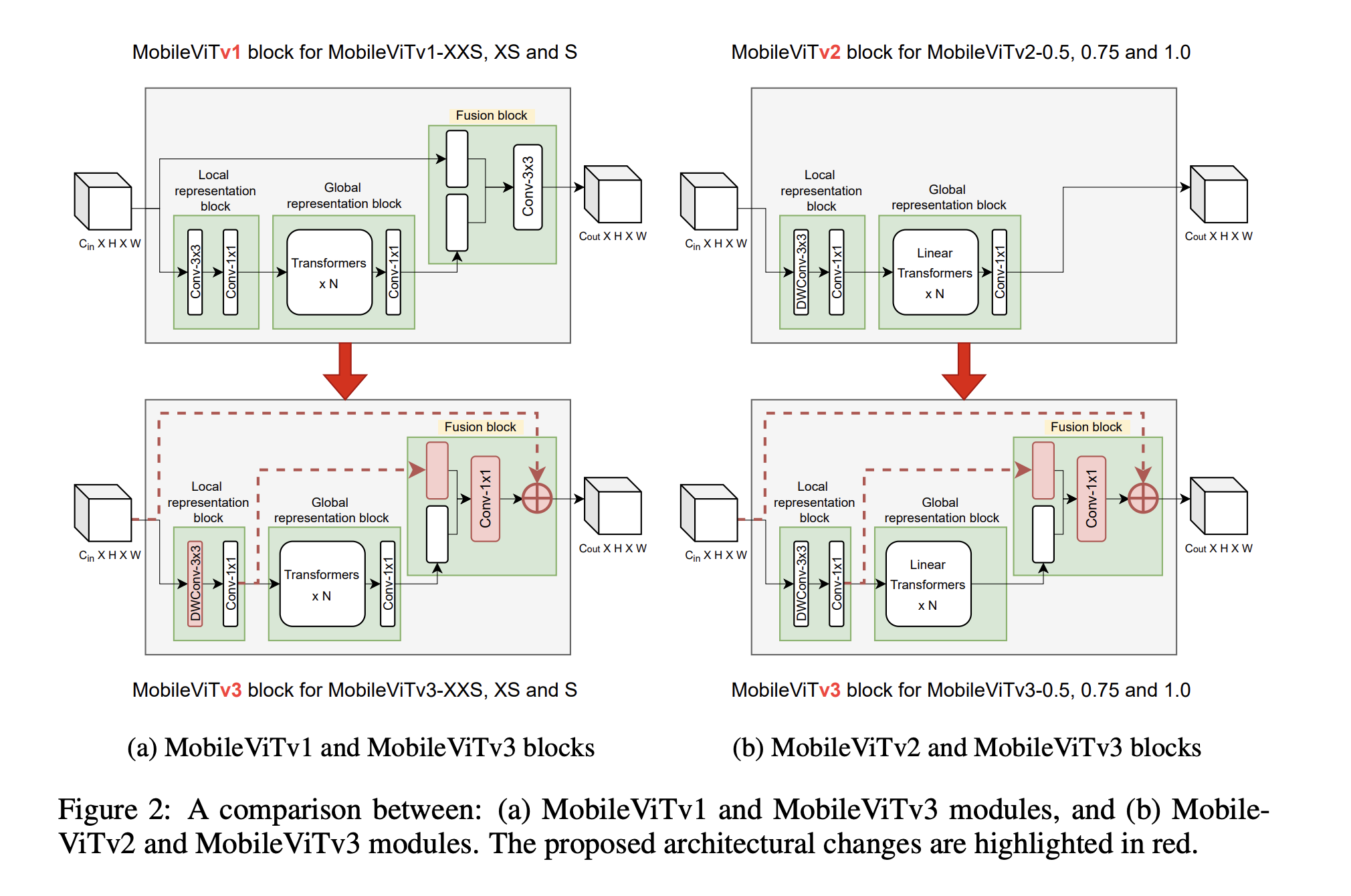
Soon, the third version of the block has been proposed in this paper.
This is deep learning engineering: 1x1 conv. layer instead of 3, depthwise convolutional layer (remember 3x3 case).
XCiT: Cross-Covariance Image Transformers¶
XCiT: Cross-Covariance Image Transformers paper proposes another way of tackling the problem with attention
The idea is interesting: take attention along feature dimension:
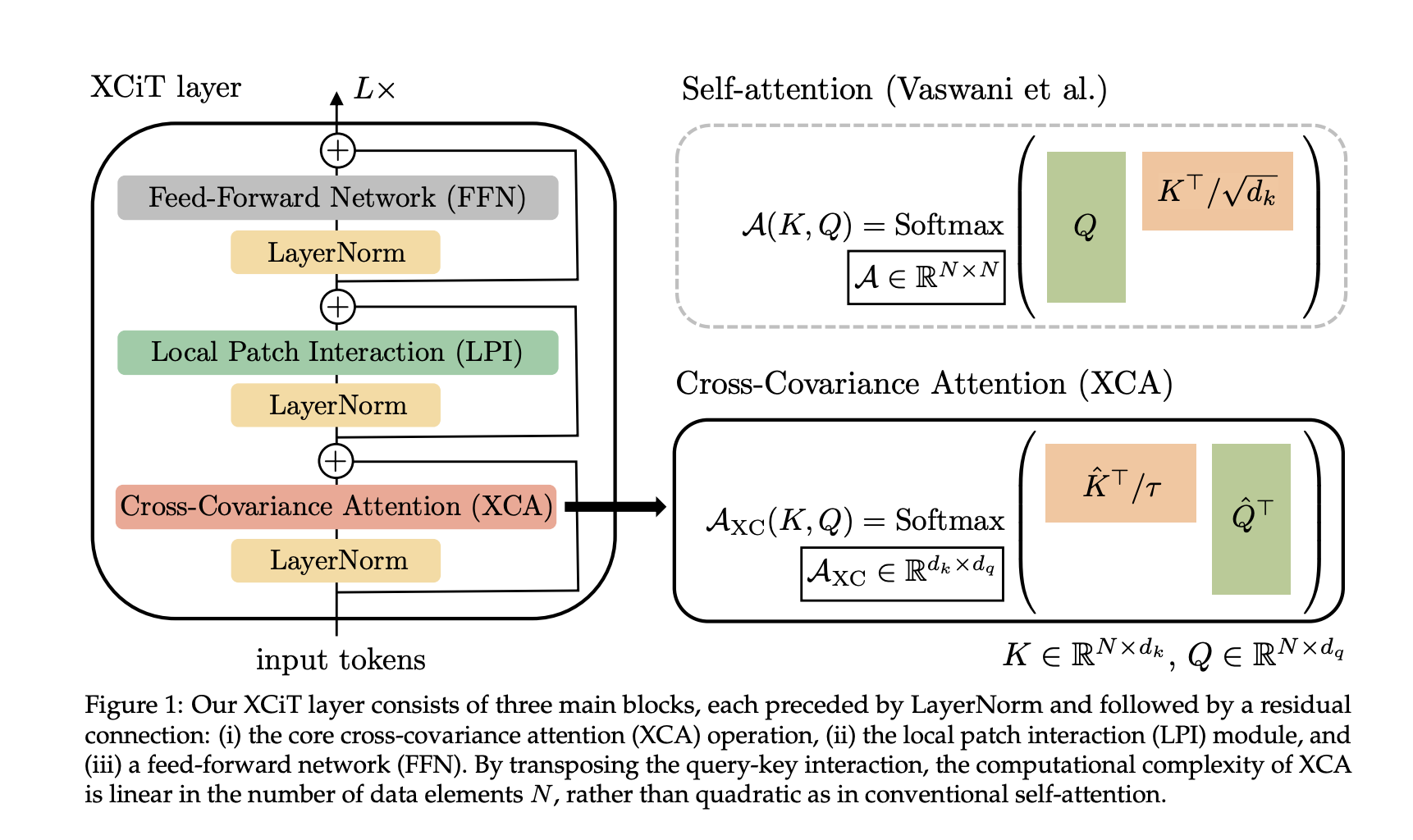
Very fast in practice. Not sure if it was not combined with other innovations.
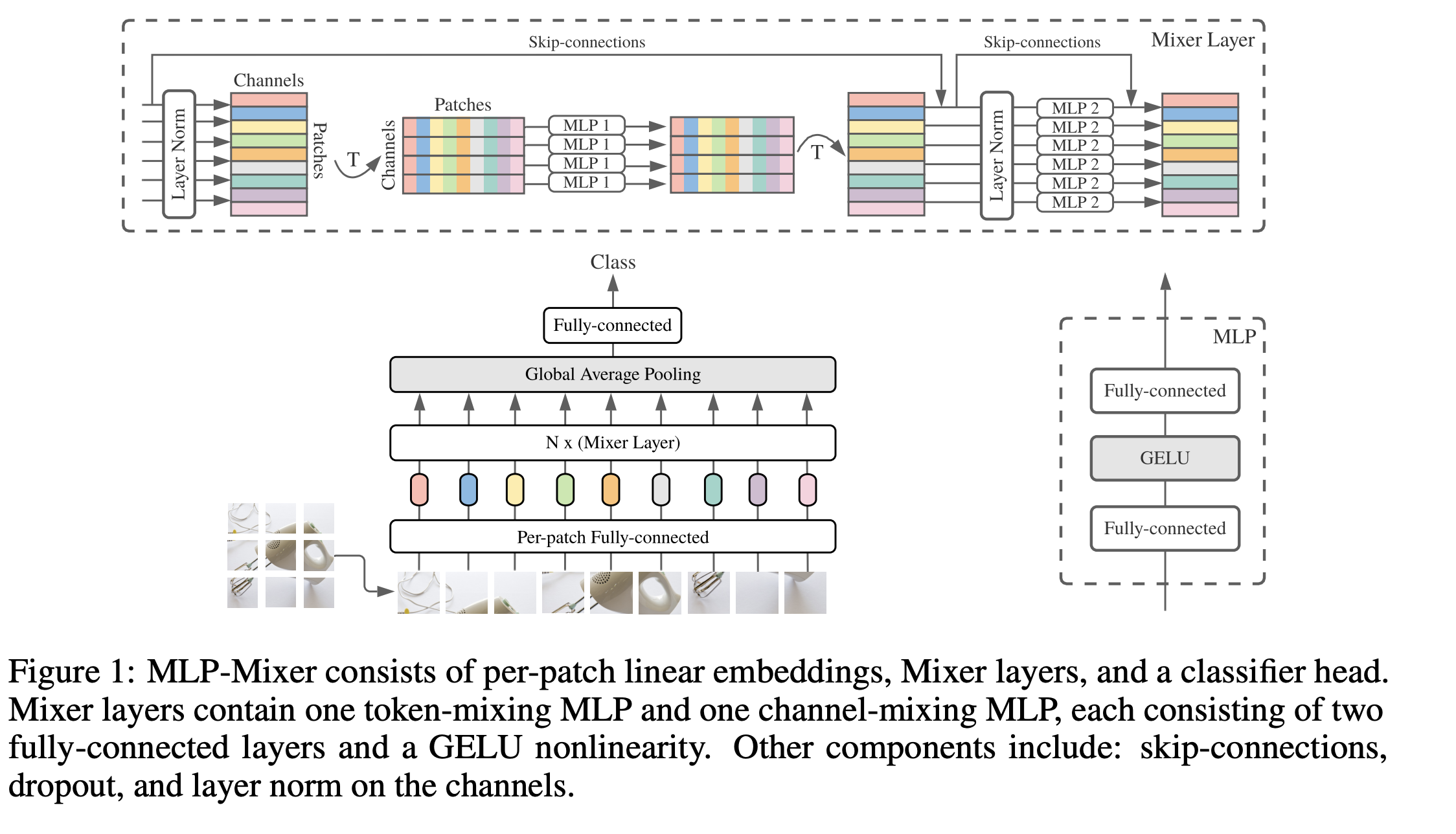
Summary¶
- Original idea of VIT
- Beit (3 versions)
- Cait
- Cross-ViT
- Transformers for object detection
- DINO
- MobileVIT (3 versions)
- XCiT
- MLP-Mixer
Next lecture: Graph neural networks¶
- Deep learning on graphs
- Basic models
- Applications