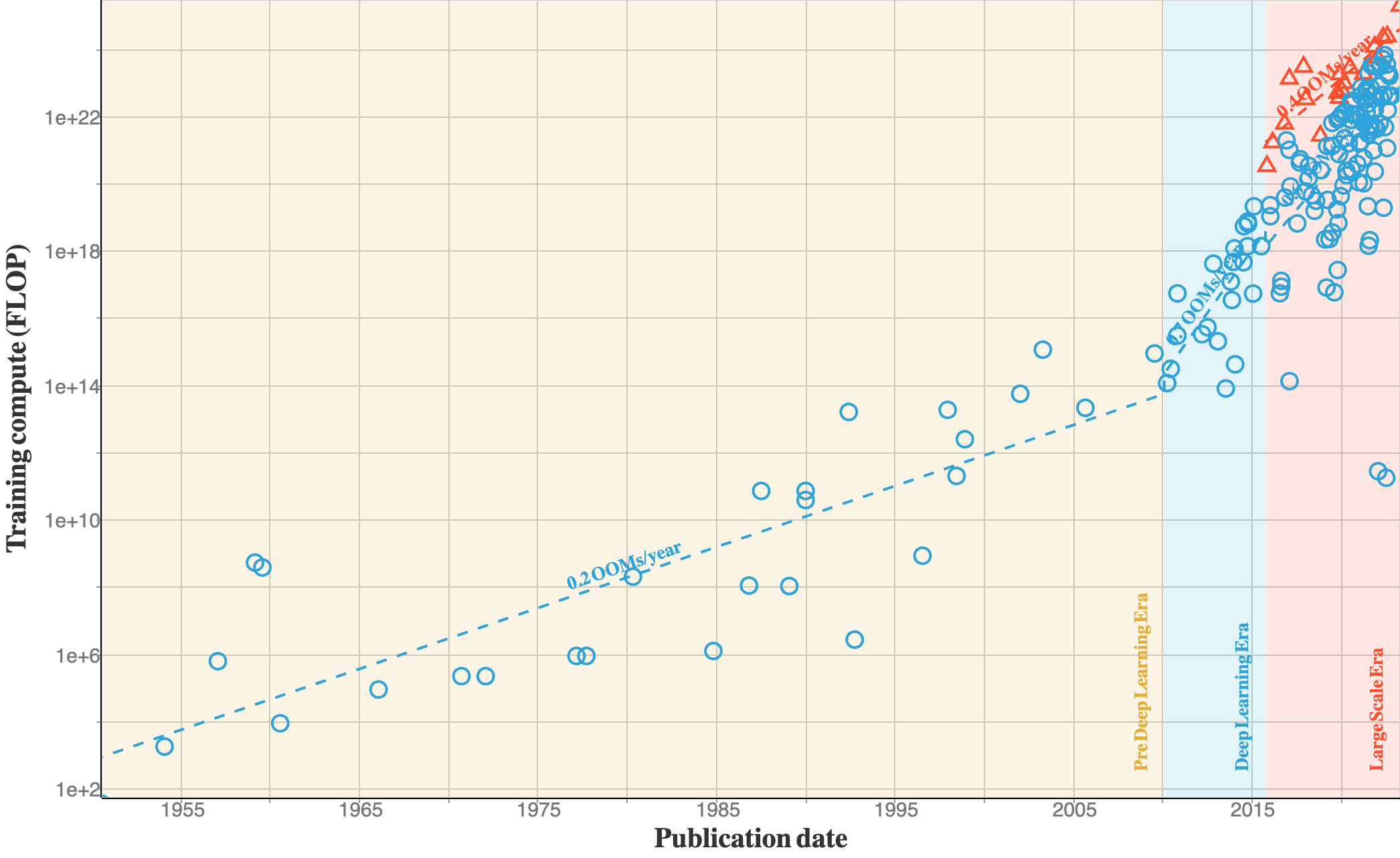
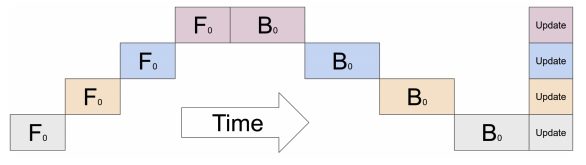
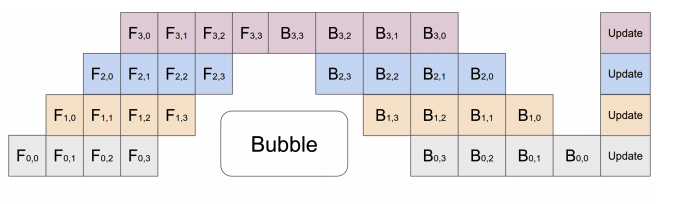
Models are getting larger and larger, and requiring larger compute¶
Also, the computational trends are quite interesting, and can be splitted into 3 different eras.
The analysis is taken from here
The Pre-Deep Learning Era: Prior to Deep Learning, training compute approximately follows Moore’s Law, with a doubling time of approximately every 20 months.
The Deep Learning Era: This starts somewhere between 2010 and 2012, and displays a doubling time of approximately 6 months.
The Large-Scale Era: Arguably, a separate trend of of models breaks off the main trend between 2015 and 2016. These systems are characteristic in that they are run by large corporations, and use training compute 2-3 orders of magnitude larger than systems that follow the Deep Learning Era trend in the same year. Interestingly, the growth of compute in these Large-Scale models seems slower, with a doubling time of about 10 months.