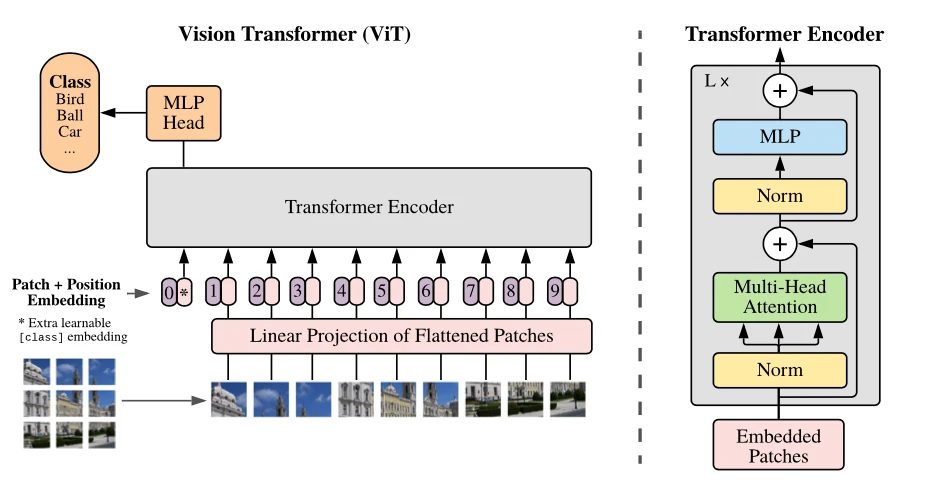
class ViT(nn.Module):
def __init__(
self,
img_size=(224, 224),
patch_size=16,
in_chans=3,
num_classes=10,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4,
norm_layer=nn.LayerNorm,
act_layer=nn.GELU
):
# Your code is here
super().__init__()
self.patch_size = patch_size
self.blocks = nn.Sequential(*[
Block(embed_dim, num_heads, mlp_ratio, act_layer, norm_layer) for _ in range(depth)
])
self.patch_proj = nn.Linear(3 * patch_size * patch_size, embed_dim)
self.embed_len = (img_size[0] * img_size[1]) // (patch_size * patch_size)
self.pos_embed = nn.Parameter(torch.randn(1, self.embed_len, embed_dim) * .02)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x):
'''
Args:
x: (batch_size, in_channels, img_size[0], img_size[1])
Return:
(batch_size, num_classes)
'''
x = img2patches(x, patch_size=self.patch_size)
x = self.patch_proj(x)
x = x + self.pos_embed
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1)
x = self.blocks(x)
x = x[:, 0, :] # take CLS token
return self.head(x)